0. 목차
1. 안전 영역 풀이 (with 재귀 dfs)
2. 정렬 알고리즘 정리 - 버블, 선택, 삽입 정렬 + 힙 정렬까지
1. 안전 영역 풀이 (with 재귀 DFS)
안전 영역은 백준 알고리즘 #2468번 문제다. 문제 내용이 기니 링크를 타고서 직접 확인해보도록 하자.
이 문제는 재귀를 이용한 DFS 방식으로 푼다. 재귀는 자기 자신을 호출하면서 스택처럼 쌓이기 때문에 DFS를 구현하기에 좋은 알고리즘이다.
*재귀와 스택 관련 내용은 아래 링크에서 확인하기.
https://ko.javascript.info/recursion
재귀와 스택
ko.javascript.info
곧바로 풀이로 넘어간다. 풀이는 다음 링크를 참고해 풀었다.
풀이를 소개하기 전, 먼저 설정해야 할 조건이 하나 있다. 본 풀이 방법은 재귀를 이용하는데, 파이썬에서는 쌓을 수 있는 재귀 스택에 제한이 걸려 있다. 이를 해지하는 메소드 setrecursionlimit을 import한다.
#스택 제한 풀기
from sys import setrecursionlimit, stdin
setrecursionlimit(100000)
#문제 입력 받기
N = int(stdin.readline())
safe_list = []
zone: List[List[int]] =[list(map(int, stdin.readline().split())) for _ in range(N)]
풀이는 크게 두 단계로 나뉜다.
1. dfs 메소드 구현하기
이 문제에서 dfs 메소드를 구현하는 방식은 재귀가 스택으로 쌓이는 개념을 활용해서 재귀를 이용한 DFS 방식으로 문제를 풀었다. 문제에서 주어진 이차원 배열을 zone이라고 하자. 인접 영역은 상하좌우에만 해당되므로, zone[i][j]를 선택하면 얘의 상하좌우 한 칸씩 중 물에 잠기지 않은 애를 스택에 쌓는다. 여기에서 가장 나중에 쌓인 애를 꺼내서 그 애를 기준으로 재귀를 돌려 다시 상하좌우 한 칸씩 중 물에 잠기지 않은 애를 계속 쌓는 식으로 DFS를 구현한다.
이때, 스캔 방향을 dx&dy로 설정해주는 개념을 이해해야 한다. 이걸 생각 못해서 오답에서는 처음에 DFS를 배울 때처럼 그래프를 일일이 만들어야 하나..하고 삽질을 오지게 했음..
코드를 보자.
# 방향:상 우 좌 하
dx = [-1, 0, 1, 0] # 상하
dy = [0, -1, 0, 1] # 좌우
def dfs(x, y, h):
# m은 각 방향을 돌면서 x, y를 기준으로 상 우 좌 하 한 칸씩을 호출한다.
for m in range(4):
nx = x + dx[m]
ny = y + dy[m]
# nx, ny가 이차원 배열 바깥에 있지 않고 방문도 하지 않았으며 물에도 잠기지 않았다면
if (0 <= nx < N) and (0 <= ny < N) and not visit[nx][ny] and zone[nx][ny] > h: # 여기에도 zone[nx][ny] > h 가 들어 있어야 => 다음 재귀에서는 이 조건이 빠지니까
#방문 표시 해주고 (기록)
visit[nx][ny] = True
#해당 nx를 기준으로 다시 재귀 => 스택! 여기서 x, y를 기준으로 다른 방향 nx, ny는 밑 접시에서 기다리고 있는 중..
dfs(nx, ny, h) #이때 이걸 return으로 작성하면 오류가 뜬다..! +1해서 값이 나온다.
2. 삼중 for 문을 돌려서 이차원 배열 스캔
물의 높이를 바꿔가며 이차원 배열을 각 물의 높이 당 한 번 씩 전체를 스캔하고 각 스캔에 대한 최대 영역 개수를 비교하며 각 스캔 별 최대 영역 값 중 최대값을 뽑아낸다.
for 1: 처음에는 물의 높이 h를 0부터 max값까지 돌리면서
for 2: 주어진 이차원 배열의 행을 돌리고
for 3: 이차원 배열에서 열을 돌린다.
ans = 1
# 삼중 for문
for k in range(max(map(max, zone))):
count = 0
visit = [[False] * N for _ in range(N)] # h 바뀔 때마다 visit 리셋해줘야 함!
for i in range(N):
for j in range(N):
if zone[i][j] > k and not visit[i][j]:
count += 1
visit[i][j] = True
dfs(i, j, k)
ans = max(ans, count)
print(ans)
전체 코드는 아래와 같다.
from sys import stdin, setrecursionlimit
from typing import List
setrecursionlimit(100000)
N = int(stdin.readline())
safe_list = []
zone: List[List[int]] =[list(map(int, stdin.readline().split())) for _ in range(N)]
dx = [-1, 0, 1, 0] # 상하
dy = [0, -1, 0, 1] # 좌우
def dfs(x, y, h):
for m in range(4):
nx = x + dx[m]
ny = y + dy[m]
if (0 <= nx < N) and (0 <= ny < N) and not visit[nx][ny] and zone[nx][ny] > h: # 여기에도 zone[nx][ny] > h 가 들어 있어야 => 다음 재귀에서는 이 조건이 빠지니까
visit[nx][ny] = True
dfs(nx, ny, h) #이걸 return으로 작성하면 오류가 뜬다..! +1해서 값이 나온다.
ans = 1
for k in range(max(map(max, zone))):
count = 0
visit = [[False] * N for _ in range(N)] # h 바뀔 때마다 visit 리셋해줘야 함!
for i in range(N):
for j in range(N):
if zone[i][j] > k and not visit[i][j]:
count += 1
visit[i][j] = True
dfs(i, j, k)
ans = max(ans, count)
print(ans)2. 정렬
오늘 목표는 정렬 알고리즘 싹 다 보는 것이었는데..아쉽게도 다는 못 끝냄..
이전에 공부했던 내용에 더해서 오늘까지 정리한 건
버블 정렬
선택 정렬
삽입 정렬
힙 정렬
도수 정렬
이렇게 총 5가지 정렬이다.
마음 같아서는 충분히 시간을 들여가며 지금까지 배운 것이라도 잘 정리해놓고 싶지만 내일이 1주차 알고리즘 시험인지라..ㅠ 빠르게..
0. 정렬
정렬은 데이터를 항목값의 대소 관계에 따라 데이터 집합을 일정한 순서로 바꾸어 늘어놓는 작업을 말한다. 데이터를 정렬하는 이유는 더 쉽게 검색이 가능하기 때문이다. 즉, 데이터를 빠르게&쉽게 찾기 위해!
정렬 알고리즘의 핵심은 교환&선택&삽입이다.
1. 버블 정렬
가장 직관적이고 가장 효율이 안 좋은(ㅆㄹㄱ..) 정렬. 시간 복잡도는 O(n^2)인데, 버블&선택&삽입 모두 O(n^2)이나 그 중에서도 버블 정렬이 가장 높은 시간 복잡도를 지닌다.
방식은 매우 간단하다. 이웃한 두 원소의 대소 관계를 비교해 필요에 따라 교환을 반복하는 알고리즘이다. 그래서 단순 교환 정렬이라고도 한다.
이해를 돕기 위해 노마드 코더 영상을 참조했다.
1. 두 이웃 원소 비교

2. 정렬하려는 방향으로 대소 관계가 바뀌어 있으면 서로 뒤바꾼다.
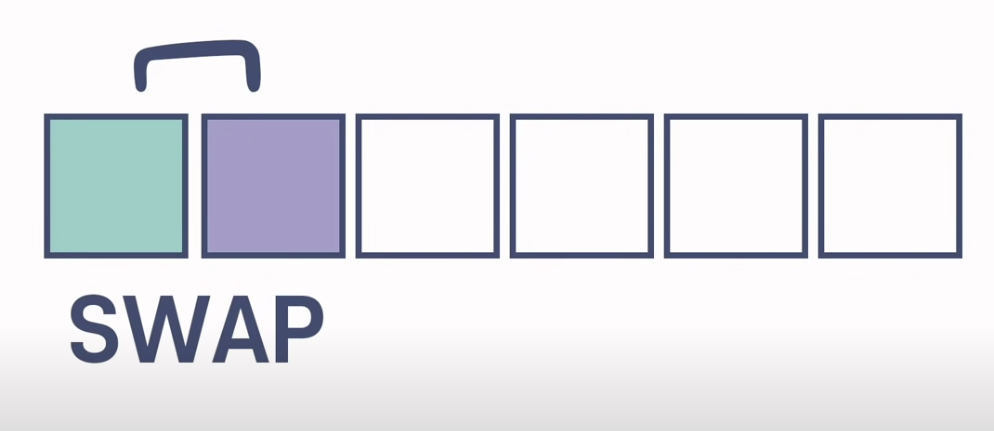
3. 이를 정렬하려는 방향으로 반복!

2. 선택 정렬
단순 선택 정렬은 가장 작은 원소부터 선택해 알맞은 위치로 옮기는 작업을 반복하며 정렬하는 알고리즘이다. 교환 과정은 다음과 같다.
- 아직 정렬하지 않은 부분에서 값이 가장 작은 원소 a[min]을 선택한다.
- a[min]과 아직 정렬하지 않은 부분에서 맨 앞에 있는 원소를 교환한다.

이 과정을 n-1번 반복하면 정렬 x 영역이 없어지면서 전체 정렬이 완료된다.
3. 삽입 정렬
(잠시 생략. 오늘은 힙 정렬 먼저 하고 나중에 다시 와서 정리하기로.. 기다려라 주말)
4. 힙 정렬
사실 앞에 1, 2, 3은 개념은 이해하는 게 좋으나 잘 쓰지는 않는 정렬인 것으로 보인다. 오히려 뒤의 퀵, 머지, 힙과 같은 애들이 더 중요하다고 한다(근데 앞에서 시간 다 날림...망할).
힙 정렬도 주요 개념만 적어놓고 보다 자세한 내용은 주말에 추가 정리하기로.
힙 정렬의 경우 나동빈 유튜브 강의를 참고했다.
힙 정렬을 이해하기 위해서는 먼저 binary tree(이진 트리)를 이해해야 한다. 이진 트리란, 모든 노드의 자식 노드가 2개 이하인 트리 구조를 의미한다. 바로 이미지를 보자.
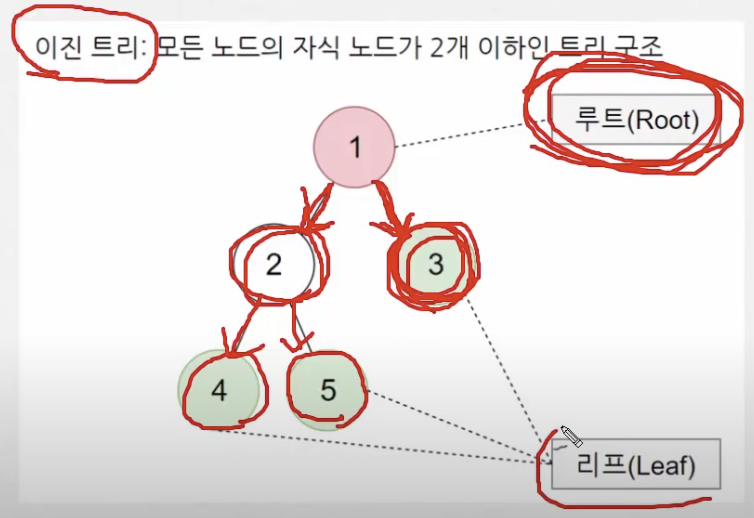
위와 같이 트리 구조가 있는데, 이때 위에 있는 노드(동그라미)가 부모 노드, 아래 있는 노드가 자식 노드이다. 최상단 부모, 가장 조상 노드를 루트, 가장 아랫단에 있는 애기가 리프 노드이다. 기본적으로 이진 트리는 각 노드마다 2개 이하의 자식 노드가 달려있을 수 있다. 위를 보면 3번 노드에는 아무 것도 달려있지 않은데, 이는 자식 노드가 0개인 상황이다.
한편, 3번 노드에 1개 자식 노드만 달려 있는 것 역시 이진 트리라고 할 수 있다. 하지만, 만약 3번 노드에 3개의 자식 노드가 달린다? 이런 건 이진 트리로서 있을 수 없는 상황이라고 보면 되겠다.
이 중에서도, 왼쪽에서부터 차근차근 하나씩 자식 노드가 달리는 이진 트리 구조를 완전 트리 구조(Complete binary tree)라고 한다. 어떤 것인지 이미지를 보자.
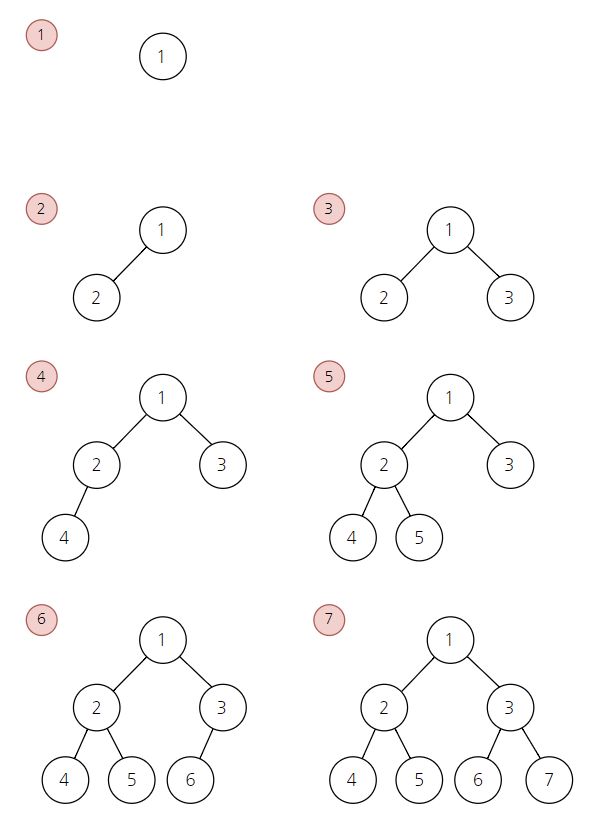
위에서부터 각 노드마다 왼쪽에서부터 자식 노드가 하나씩 채워지는 것을 볼 수 있다.
이제 본격적으로 힙 정렬을 알아보자. 힙 정렬은 위와 같은 완전 이진 트리 구조를 기반으로 한 정렬이다. 보는 것처럼 루트에 최솟값(혹은 최댓값)을 넣을 수 있으니 어떤 자식 노드에서 출발해도 쓸데없는 곳을 거치지 않고 빠르게 최상단으로 달려갈 수 있는 구조이다. 따라서 최솟값 혹은 최댓값을 빠르게 찾아낼 수 있다.
힙에는 최소 힙과 최대 힙이 존재한다. 각각 최상단에 최솟값과 최댓값이 들어가는 구조다.
힙 정렬을 만들기 위해서는 먼저 데이터가 이진 트리 구조를 따라야 한다.
예제를 살펴보자. 먼저 최대 힙을 보면, 루트에 최댓값이 들어가야 하니 자식 노드는 부모 노드보다 무조건 작은 값을 가져야 한다.

그런데 정렬하는 과정에서 중간에 부모보다 자식이 더 큰 경우도 있을 것이다. 이를 힙이 붕괴되었다고 하는데, 이런 경우를 만나면 부모에 연결된 자식 노드 중 더 큰 값을 위로 올리면 된다. 아래 그림을 보자.

밑의 자식 노드에 7과 4가 있고, 부모 노드는 5이다. 이 경우, 7이 4와 5보다 크니 7을 부모로 올리고 5를 밑으로 내린다.
이렇게 힙 정렬을 수행하는 알고리즘을 힙 정렬 알고리즘(Heapify Algorithm)이라고 한다. 더 자세한 건 주말에 계속...
'정글사관학교 개발일지 > 자료구조&알고리즘' 카테고리의 다른 글
| 정글사관학교 12일차 TIL: 이진 탐색(Binary Search), 파라메트릭 서치 (0) | 2021.11.13 |
|---|---|
| 정글사관학교 11일차 TIL: 숫자 야구(#2503), 독일 로또(#6603) (0) | 2021.11.12 |
| 정글사관학교 9일차 TIL: BFS & DFS, 큐와 스택 (0) | 2021.11.10 |
| 정글사관학교 8일차 TIL: Dynamic Programming(DP), 외판원 순회 문제(TSP) (0) | 2021.11.09 |
| 정글사관학교 6일차 TIL: 재귀, 정렬 알고리즘 (0) | 2021.11.07 |