0. 목차
1. BFS
- 큐
2. DFS
- 스택
오늘은 사족 없이 빠르게 가보자.
아래와 같이 두 그래프가 있다. 보다시피 그래프 자체는 동일하다. 하지만 어디서부터 데이터를 읽어오는지 그 순서가 다르다.
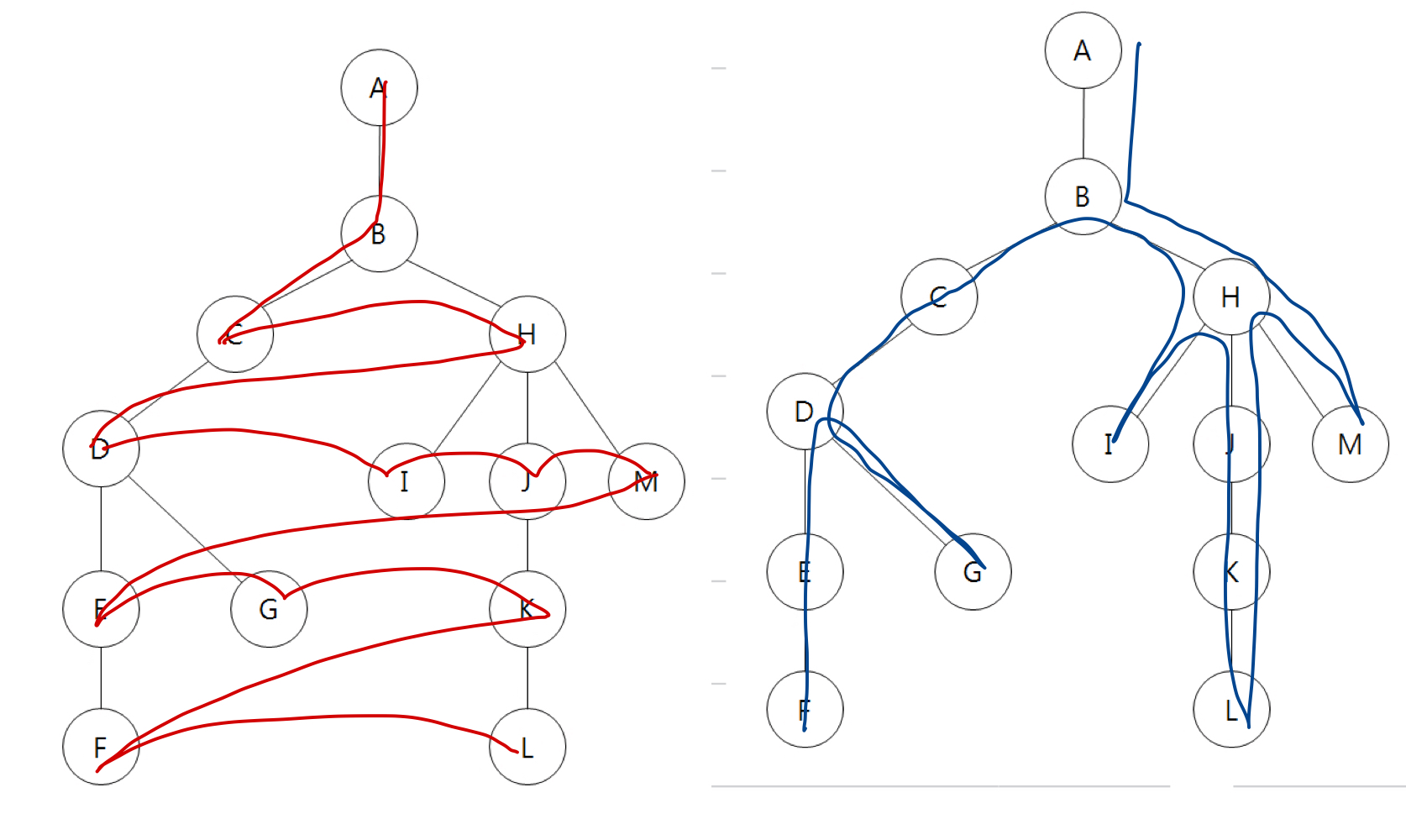
1. BFS (Breath First Search)
왼쪽의 빨간 경로는 너비 우선 탐색인 BFS에 해당한다. 시작 노드에서 가까운 노드부터 순서대로 방문하는 탐색 알고리즘이다. 오른쪽의 DFS는 보다시피 경로 하나하나가 깊이를 주구장창 파는 반면, BFS에서는 시작 노드를 기준으로 동일한 레벨(=뎁스)에 있는 노드를 병렬적으로 방문하는 방식이다.
이를 구현하는 방식을 이해하려면 큐(Queue) 자료구조를 이해할 필요가 있다.
언젠가 큐와 스택을 구별하는 아주 명쾌한 설명을 읽은 적이 있는데, 큐는 놀이동산에서 늘어선 줄, 스택은 쌓은 접시라고 이해하면 매우 편하다. 여기서 큐를 설명하고 뒤의 DFS에서 스택을 마저 설명하겠다.

놀이동산에서 줄을 섰다고 생각해보자. 먼저 줄 선 사람이 먼저 탑승하러 들어가고 늦게 온 사람은 기다렸다가 자기 차례가 됐을 때 나가는(First-In, First-Out) 구조가 바로 큐(Queue)이다. 이게 저 위의 그래프와 어떻게 매칭이 될지 잘 감이 오지 않을 것이다. 오히려 줄 선 다고 생각하니 오른쪽의 DFS와 비슷한 거 아닌가..? 싶기도 할 것이다. 바로 코드를 보자.
먼저, 실습을 위해 위의 그래프를 딕셔너리로 구현한다.
graph = {
'A': ['B'],
'B': ['A', 'C', 'H'],
'C': ['B', 'D'],
'D': ['C', 'E', 'G'],
'E': ['D', 'F'],
'F': ['E'],
'G': ['D'],
'H': ['B', 'I', 'J', 'M'],
'I': ['H'],
'J': ['H', 'K'],
'K': ['J', 'L'],
'L': ['K'],
'M': ['H']
}
아래 코드에서는 실습할 때 이해를 돕기 위해 주석에 print 문을 추가해놨으니 같이 실행해봐도 좋다.
#BFS: Queue 자료구조를 사용 => Q는 줄서기.
# 노드를 방문하면서 인접한 노드 중 방문하지 않았던 노드의 정보만 큐에 넣어 먼저 큐에 들어있던 노드부터 방문.
# Queue는 FiFO: First in, First Out => 먼저 온 애가 먼저 나간다. 줄서기 개념.
# 파이썬에서 큐를 list 타입으로 사용할 때는 뒤에서 넣으니까 append()를 쓰고, 나갈 때는
def bfs(graph, start_node):
visit = list()
queue = list()
queue.append(start_node)
# print("Start_node is: ", start_node)
# print("queue is: ", queue)
while queue:
node = queue.pop(0)
# print('node is: ', node)
# print("queue is now: ", queue)
if node not in visit:
# print(f"새로운 방문지입니다. {node}를 visit에 추가합니다.")
visit.append(node)
# print("visit is now: ", visit)
# print("graph[node] is: ", graph[node])
queue.extend(graph[node])
# print("Queue is after: ", queue)
return visit
#print(bfs(graph, 'A'))위의 코드를 풀어서 써보자.
1. 먼저 위의 이미지에서 보다시피 시작 노드는 A에서 출발한다. (start_node == A)
2. visit, queue라는 빈 리스트를 생성한다.
3. queue에 start_node를 append한다. (줄 세우기: start_node부터 줄 선다.)
4. while queue: queue 리스트 안에 값이 있다면 => 앞에서 start_node에 값을 넣었으니 True. 아래 코드를 실행한다.
5. node = queue.pop(0) => queue 안에 있던 애들 중 제일 앞의 노드를 pop(0)으로 빼낸다(Queue). 현 상태에서는 queue에 start_node만 들어 있으니 node = start_node가 된다.
6. if node not in visit: 현재 아무 곳에도 방문한 적 없으니 시작 노드를 visit에 append한다.
7. queue에다가 A 노드와 연결된 다른 노드(B)를 extend한다.
8. 다시 while 문: 이번에는 queue에 B만 있으니 같은 행위를 반복.
9. visit에는 [A, B]가 쌓이고 queue에는 B와 연결된 노드인 C, H가 순차적으로 Queue에 줄을 선다.
Queue = [C, H]
Visit = [A, B]
이때가 중요한데, 앞서 말했던 것처럼 Queue는 앞에서 온 놈이 먼저 실행된다. H는 줄을 서고 있고 C가 실행되면 C는 visit에 추가되며 C와 연결된 노드가 H 뒤에 줄을 선다! C와 연결된 노드는 B, D이므로 B와 D가 H 뒤에 줄을 선다.
Queue = [H, B, D]
Visit = [A, B, C]
H는 C와 동일한 뎁스에 있는 친구다. 여기서부터 보는 것처럼 BFS가 시행되고 있음을 알 수 있는데, 한 줄만 더 해보면 H는 visit으로 들어가고 Queue에는 H와 연결된 노드인 B, I, J, M이 기존의 Q에 들어있는 B, D 뒤로 줄을 선다.
Queue = [B, D, B, I, J, M]
Visit = [A, B, C, H]
이런 식으로 계속해서 같은 뎁스에 있는 애들을 병렬적으로 탐색하는 게 BFS이다.
(참고)
*append(x)와 extend(x)의 차이:
append(x)는 x를 리스트 끝에 그대로 넣는다. 그게 값이건 리스트건 그냥 추가.
extend(x)는 리스트 끝에 가장 바깥쪽 iterable의 모든 항목을 넣는다. 쉽게 말해 셀 수 있는 원소만 넣는 개념.
ex1 - x가 리스트일 때: x = [4, 5])
list = [1, 2, 3]
append: list.append(x) = [1, 2, 3, [4, 5]]
extend: list.append(x) = [1, 2 ,3, 4, 5] (*원소로 들어감!)
ex2 - x가 문자열일 때: x = "list")
list = ["Hi", "Hello"]
append: list.append(x) = ["Hi", "Hello", "list"]
extend: list.extend(x) = ["Hi", "Hello", "l", "i", "s", "t"]
1. DFS (Depth First Search)
위 이미지에서 오른쪽의 파란 경로는 깊이 우선 탐색인 DFS다. 앞서 말한 것처럼, DFS는 경로 하나하나 들어갈 때마다 깊이를 주구장창 파는 방식이다. 계속해서 시작 노드와 멀어지는 방식이라고 생각하면 되겠다.
이번에도 역시 DFS를 설명하기 앞서 스택(Queue) 자료구조를 살펴보자.
위에서 말했듯 큐는 놀이동산에서 늘어선 줄, 스택은 쌓은 접시다.

접시를 쌓아놨다고 생각해보자. 앞에서처럼 큐 구조에 접시를 대입해보면 가장 맨 밑에 있는 접시가 가장 먼저 왔으니, 가장 먼저 나가야될텐데.. 딱 봐도 와장창 엄마 등짝 스매시 각이다. 그러니 맨 위 접시부터 나가야 가정의 평안이 오지 않겠나? 이를 고급지게 말하면 LIFO(Last-In, First-Out: 가장 늦게 들어온 애가 가장 먼저 나간다.) 구조라고 한다. 이것이 바로 스택(Stack)이다.
여기서도 더 길게 말할 것 없이 바로 코드를 보자.
이번에는 코드를 보면 좀 재밌을 텐데, 위의 BFS와 잘 비교해보면서 보면 좋을 것이다.
#DFS: Stack 자료구조를 사용 => Stack은 접시 쌓기
# 노드를 방문하면서 인접한 노드 중 방문하지 않았던 노드의 정보를 스택에 넣고 가장 나중에 들어온 노드부터 방문.
# Stack는 LIFO: Last In, First Out => 늦게 온 애가 먼저 시행된다.
# 파이썬에서 큐를 list 타입으로 사용할 때는 뒤에서 넣으니까 append()를 쓰고, 나갈 때는 pop()
def dfs(graph, start_node):
visit = list()
stack = list()
stack.append(start_node)
# print("Start_node is: ", start_node)
# print("stack is: ", stack)
while stack:
node = stack.pop()
# print('node is: ', node)
# print("stack is now: ", stack)
if node not in visit:
# print(f"새로운 방문지입니다. {node}를 visit에 추가합니다.")
visit.append(node)
# print("visit is now: ", visit)
# print("graph[node] is: ", graph[node])
stack.extend(graph[node])
# print("stack is after: ", stack)
return visit
#print(dfs(graph, 'A'))뭔가 이상한 걸 느낄텐데, 그렇다. 변수 queue를 => stack이라는 이름으로 바꾸고, pop(0)에서 pop()으로 바꾼 것 외에는 아무 것도 건들지 않았다. 그저 리스트에서 맨 앞에서 빼냐(Queue) 맨 뒤에서 빼냐(Stack)에 따라 너비 탐색/ 깊이 탐색이 결정된다. 신기하지 않나?
이번에도 코드를 풀어서 써본다.
1. 시작 노드는 A에서 출발한다. (start_node == A)
2. visit, queue라는 빈 리스트를 생성한다.
3. stack에 start_node를 append한다. (접시 쌓기: start_node가 맨 아랫 접시에 쌓인다.)
4. while stack: stack 리스트 안에 값이 있다면 => 앞에서 start_node에 값을 넣었으니 True. 아래 코드를 실행한다.
5. node = stack.pop() => stack 안에 있던 애들 중 제일 뒤에 있는(=접시 개념으로는 제일 위에 있는) 노드를 pop()으로 빼낸다(stack). pop()은 인자를 받지 않으면 가장 뒤에 있는 값을 빼낸다. 현 상태에서는 stack에 start_node만 들어 있으니 node = start_node가 된다.
6. if node not in visit: 현재 아무 곳에도 방문한 적 없으니 시작 노드를 visit에 append한다.
7. stack에다가 A 노드와 연결된 다른 노드(B)를 extend한다.
8. 다시 while 문: 이번에는 stack에 B만 있으니 같은 행위를 반복.
9. visit에는 [A, B]가 쌓이고 stack에는 B와 연결된 노드인 C, H가 순차적으로 Stack에 줄을 선다.
Stack = [C, H]
Visit = [A, B]
이때가 중요한데, Stack는 맨 나중에 온 놈이 먼저 실행된다. C는 계속 줄을 서고 있고 H가 빠져나와서 실행되면 H는 visit에 추가되며 H와 연결된 노드가 C 뒤에 줄을 선다! H와 연결된 노드는 B, I, D이므로 B와 D가 H 뒤에 줄을 선다.
Queue = [H, B, D]
Visit = [A, B, C]
H는 C와 동일한 뎁스에 있는 친구다. 여기서부터 보는 것처럼 BFS가 시행되고 있음을 알 수 있는데, 한 줄만 더 해보면 H는 visit으로 들어가고 Queue에는 H와 연결된 노드인 B, I, J, M이 기존의 Q에 들어있는 B, D 뒤로 줄을 선다.
Queue = [B, D, B, I, J, M]
Visit = [A, B, C, H]
이런 식으로 계속해서 같은 뎁스에 있는 애들을 병렬적으로 탐색하는 게 BFS이다.
Further study 1
위에서는 큐와 스택을 구현하기 위해 자료구조로는 리스트를, 방법으로는 append와 pop을 사용했다. 하지만 리스트는 스택은 괜찮으나 큐를 구현하기에는 좋지 않은 구조인데, 리스트에서 맨 앞에 있는 순번을 빼내기 위해 pop(0)을 사용하는 방식의 시간 복잡도가 O(n)에 해당하기 때문이다.
이를 보완하기 위해 deque를 쓰거나 파이썬 내장 모듈 queue를 불러와서 사용하면 O(1)의 복잡도로 작업이 가능하다.
Further study 2
위에서는 DFS를 리스트로 구현했으나, DFS는 재귀로도 구현이 가능하다. 자세한 건 다음 스터디에서!
*참고자료: Deque로 큐와 스택을 구현하는 게 리스트보다 더 효율적이라고 함!
'정글사관학교 개발일지 > 자료구조&알고리즘' 카테고리의 다른 글
| 정글사관학교 11일차 TIL: 숫자 야구(#2503), 독일 로또(#6603) (0) | 2021.11.12 |
|---|---|
| 정글사관학교 10일차 TIL: 안전 영역 문제 풀이, 정렬 알고리즘 정리(버블 정렬, 선택 정렬, 삽입 정렬, 힙 정렬) (0) | 2021.11.11 |
| 정글사관학교 8일차 TIL: Dynamic Programming(DP), 외판원 순회 문제(TSP) (0) | 2021.11.09 |
| 정글사관학교 6일차 TIL: 재귀, 정렬 알고리즘 (0) | 2021.11.07 |
| 정글사관학교 4일차 TIL: 알고리즘 풀이, 문제해결이란 무엇인가 (0) | 2021.11.06 |