첫 번째 과제는 supplemental page table 구현이다. 이를 위해 supplemental page table이 무엇인지 먼저 간단히 살펴보자.
supplement page table은 이전에 정리했던 개념인 다단계 페이지
이제 과제 개요를 살펴본다.
0. 과제 개요
Implement supplemental page table management functions in `vm/vm.c`.
우리의 핀토스는 pml4라는 페이지 테이블을 갖고 있는데 얘는 가상 메모리와 물리 메모리 간 매핑을 관리한다. 하지만, 이것으로 충분치 않음. 이전 섹션에서 논의했듯, 우리는 page fault와 자원 관리를 다루기 위해서 각각 페이지에 대한 추가 정보를 들고 있는 supplementary page table이 필요하다. 따라서, 우리는 프로젝트 3 첫번째 과제로 supplemental page table에 대한 기본적인 기능을 구현할 것이다.
우리는 어떻게 supplemantal page table을 설계할 것인지를 결정해야 한다. 우리의 supplemental page table을 디자인해보자. 그 전에, Supplemental Page Table이란 놈에 대해 좀 더 알아보도록 한다.
Supplemental Page Table(SPT)
SPT는 위에서 설명한 것처럼 page fault 발생, 그리고 자원 관리를 위해 각 페이지에 대한 추가 정보를 들고 있는 페이지 테이블을 말한다. 기존에 공부했던 multi-level page table과는 또 다른 테이블이다. 앞서 배웠던 multilevel page table은 그 목적이 실제 사용하는 페이지만을 여러 단계에 걸쳐 페이지 테이블에 할당해줌으로써 페이지 테이블 공간 복잡도를 줄이는 것이다. 반면, 얘는 아래 두 가지 역할을 수행한다.
- Page fault시 커널이 supplement 페이지 테이블에서 오류가 발생한 가상 페이지를 조회하여 어떤 데이터가 있어야 하는지를 확인할 필요가 있다. 이를 위한 용도가 있으며
- 프로세스가 종료될 때 커널이 추가 페이지 테이블을 참조하여 어떤 리소스를 free시킬 것인지를 결정한다.
추가 자료를 참조하면 또 다른 두 가지 역할이 있다고 하는데, 사실 여부는 직접 구현하면서 확인해볼 예정.
- 어떤 page-table entry가 physical address를 가리키고 있는 상황에서 다른 page table entry도 같은 physical address를 가리킬 수 있다. why? page table은 page table entry마다 하나씩 가지고 있고 서로 다른 virtual address를 갖지만 같은 physical memory를 참조하는 경우가 충분히 발생할 수 있기 때문이다. 참조하는 테이블은 전부 다르지만 결국 같은 physical address를 가리키고 있는 것. 이러한 경우를 다루려면 하나의 프로세스가 어떤 physical memory를 참조하는지에 대한 정보가 필요하기에 추가 page table이 필요.
- 기존 page-table은 physical memory를 향한 일방적인 pointing에 불과하다. 때문에 physical memory의 값이 바뀌어 있으면 패닉. 기존에 어떠한 데이터가 있는지에 대한 정보를 갖고 있지 않기에 문제가 발생. supplementary page table에서는 원래 physical memory에 들어가 있어야 할 데이터가 어떤 것인지에 대한 정보를 갖는다.
이 SPT를 구현하고 나면 아래 세 가지 함수를 구현하는 것이 과제.
void supplemental_page_table_init (struct supplemental_page_table *spt);
supplemental page table을 초기화한다. 우리는 spt에 사용하기 위한 자료구조를 선택해야 한다. 이 함수는
- 새로운 프로세스가 시작할 때 호출되거나 (initd in userprog/process.c )
- 프로세스가 fork될 때 호출된다.(__do_fork in userprog.process.c)
struct page *spt_find_page (struct supplemental_page_table *spt, void *va);
주어진 spt로부터 가상주소 va와 대응하는 struct page를 찾는다. 만약 실패하면 return NULL
bool spt_insert_page (struct supplemental_page_table *spt, struct page *page);
struct page를 주어진 spt에 삽입해라. 이 함수는 가상 주소가 주어진 spt에 존재하지 않음을 반드시 체크해야 한다.
1. Supplemental page table & hash table 정리
supplement page table은 다양한 방식으로 구현할 수 있는데, 우리 팀은 해시 테이블을 선택하기로 했다. 구현할 수 있는 테이블 유형에는
- 배열(array)
- 연결리스트(linked list)
- 해시 테이블(Hash table)
- 비트맵(Bitmap)
정도가 있다고 소개한다. 각 자료구조의 장단점을 살펴보면
- array - 가장 구현이 간단하나 공간복잡도가 크다는 문제(메모리 용량을 낭비) / 시간복잡도는 O(1)
- linked list - 탐색 시 시간 복잡도 - O(n) 낭비가 크다. 리스트 역시 심플하긴 하지만, 일일이 확인하면서 찾아야 하기 때문에 시간이 낭비
- Hash table - 탐색시 시간복잡도 O(1)이라는 장점이 있으며 array와 달리 연속적인 공간을 쓰는 개념이 아니기에 공간복잡도 측면에서도 효율적.
- Bitmap - 말 그대로 해당 정보를 비트에 매핑시키는 자료구조. 비트로 정보를 저장하기에 공간 복잡도 측면에서 매우 효율적임. 구분해야 할 자료가 많지 않을 때는 이만큼 효율적인 것도 없으나 구분해야 할 서로 다른 자료가 많으면 많을수록 복잡해지는 측면이 있음.
이중 해시 테이블에 대해서 잠깐 다루면,
해시 테이블(참조1) (참조2)
해시 테이블은 key에 value를 저장하는 데이터 구조로, value :=get(key)에 대한 기능이 매우 빠르게 작동한다. 기본적인 개념을 살펴보면,
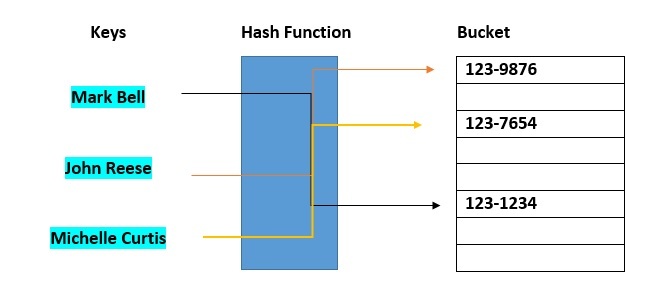
우리가 이름을 key 삼아 전화번호를 저장하는 해시 테이블 구조를 만든다고 하자. 총 16명에 대한 정보가 있으며 이 중 John Smith의 데이터를 저장한다고 하면
1. 인덱스를 먼저 구한다. index = hash_func("John Smith") % 16 => 이렇게 인덱스 값을 구한다. hash_func은 해시 함수로, 입력값(여기서는 이름)을 넣으면 언제나 동일한 값의 숫자를 반환하는 함수다.
2. 이후 해당 array[n]에 전화번호를 저장한다.
해시 함수에 key를 입력해 해시 값을 받아내는 과정에서의 시간복잡도가 O(1), 이후 테이블에서 해당 인덱스로 이동하는데 걸리는 시간이 O(1)이기에 평균 시간 복잡도가 O(1)인 매우 큰 장점이 있다.
해시 테이블의 경우 충돌 문제가 있는데(서로 다른 key에 대해 hash 함수를 돌렸을 때 같은 인덱스값이 나오는 경우) 이를 해결하기 위한 한 가지 방식으로 seperate chaning 방식이 있다. 여기 해시 테이블에서도 이를 구현해놓은듯 하다.
설명하면, 아래 그림처럼 John Smith 와 Sandra Dee에 대해 hash func이 인덱스 152를 반환한다. 이 경우에는 충돌이 발생한 것이며, 이를 해결하는 방법은 둘다 일단 같은 152에 달아놓은 다음, John Smith 다음에 Sandra Dee를 연결 리스트로 연결한다. 이렇게 되면 152를 간 다음 둘만 구분하면 되니까 충돌이 일어나도 문제가 없다. 다만 이런 방식으로 했을 때, 최악의 경우 모든 key에 대해 충돌이 일어난다면 하나의 인덱스에 전부 연결 리스트 형식으로 연결되니 시간 복잡도는 O(N)이 된다는 문제가 발생한다. 또한, 각 연결 리스트에 대해 추가 메모리 공간을 소모하기 때문에 공간복잡도 측면에서도 단점이 있다.

여기서 bucket은 해시 테이블 안에서 값이 저장되는 공간을 뜻한다. 인덱스와 1대1로 맵핑되는 공간이며 여기에 각 엔트리가 담긴다.
해시 테이블로 구현한 페이지 테이블에서, 가상 주소의 VPN은 해시 테이블로 해시 암호화되어 저장된다. 이 해시 테이블은 32비트 이상의 가상 주소를 다룰 때 주로 사용한다. 해시 테이블 내 각 엔트리는 동일한 위치에 해시된 원소의 연결 리스트를 갖는다. 이는 서로 다른 페이지 번호가 동일한 해시 함수 값을 얻는 충돌(collision)을 피하기 위해서이다. 해시 값은 가상 페이지 번호이며, 가상 페이지 번호는 페이지 오프셋 일부가 아닌 모든 비트이다.

위는 supplemental page table이 아닌 그냥 일반 page table을 다루는 것으로 보여 간단한 개요만 짚고 디테일은 구현에서 다루겠다. 보는 것처럼 해시 함수를 통해 해시 테이블에 배치하는 방식이며 해시를 이용하면 O(1)의 시간 복잡도로 해당 위치를 찾을 수 있다는 장점이 있어 유용하게 사용할 수 있다.
그러면 이제 구현으로 넘어간다.
2. Supplemental page table 구현
supplemental_page_table 구조체에 hash_elem 추가
@include/vm/vm.h
struct supplemental_page_table {
struct hash spt_hash;
};우리는 SPT 자료 구조로 hash table을 사용하기로 했으니, 해당 자료구조를 SPT 멤버에 넣어준다. hash 함수는 lib/kernel/hash.c에 이미 완성되어 있다.
Page 구조체에 hash_elem 추가
@include/vm/vm.h
struct page {
(...)
/* Your implementation */
/* --- Project 3: VM-SPT ---*/
struct hash_elem hash_elem;
// key : page->va, value : struct page
(...)
};
};해당 페이지가 속해 있는 해시 테이블에 연결해주는 해시 테이블 요소로서 hash_elem을 추가한다. key에는 page->va값이 들어가고 이에 매핑되는 value로는 페이지 구조체가 들어간다.
SPT 자료구조로 해시 테이블을 사용하기로 했으니 초기화를 진행해줘야 한다. 제공되는 hash 구조체와 함수 hash_init()을 살펴본다.
Hash 구조체
해시 테이블 구조체는 아래와 같이 생겼다. 해시 테이블에는 array와 해당 array에 달리는 linked list의 조합으로 이뤄져 있다. 가상 주소 va를 hash function을 통해 hash table의 인덱스로 변경하면 해당 인덱스에 매핑되는 bucket에는 hash_elem이 달려있어 이 hash_elem을 통해 해당 페이지를 찾을 수 있는 구조이다. 이때 충돌이 발생하면 동일한 인덱스에 hash_elem을 줄줄이 다는 식이다.
/* Hash table. */
struct hash {
size_t elem_cnt; /* Number of elements in table. */
size_t bucket_cnt; /* Number of buckets, a power of 2. */
struct list *buckets; /* Array of `bucket_cnt' lists. */
hash_hash_func *hash; /* Hash function. */
hash_less_func *less; /* Comparison function. */
void *aux; /* Auxiliary data for `hash' and `less'. */
};
hash_init()
해시 자료구조를 초기화해준다.
/* Initializes hash table H to compute hash values using HASH and
compare hash elements using LESS, given auxiliary data AUX. */
bool
hash_init (struct hash *h,
hash_hash_func *hash, hash_less_func *less, void *aux) {
h->elem_cnt = 0;
h->bucket_cnt = 4; // 0, 1, 2, 3
h->buckets = malloc (sizeof *h->buckets * h->bucket_cnt);
h->hash = hash;
h->less = less;
h->aux = aux;
if (h->buckets != NULL) {
hash_clear (h, NULL);
return true;
} else
return false;
}인자로 받는 hash_hash_func, hash_less_func는 각각 구현해줘야 하는 함수이다. 전자는 hashed index를 만드는 함수이고 후자는 hash 요소 간에 비교하는 함수. 이는 아래에서 추가로 구현할 것이다.
위에서는 buckets를 초기화할 때 malloc을 통해 동적할당으로 배열을 받아온다. 그런데 공부하다보면 뭔가 이상한 점이 있다. hash.h 에 달려있는 주석 글을 보자.
<hash.h>
<Hash table>
(...)
This is a standard hash table with chaining. To locate an element in the table, we compute a hash function over the element's data and use that as an index into an array of doubly linked lists, then linearly search the list.
이 해시 테이블은 체이닝 방식의 표준 해시 테이블이다. 테이블 내에 원소를 위치시키기 위해, 해시 함수로 원소의 값을 계산해 변환하고, 이를 인덱스로 사용해 이중 연결리스트의 배열에 삽입한다. 이후, 리스트를 선형으로 검색한다.
The chain lists do not use dynamic allocation. Instead, each structure that can potentially be in a hash must embed a struct hash_elem member. All of the hash functions operate on these `struct hash_elem's. The hash_entry macro allows conversion from a struct hash_elem back to a structure object that contains it. This is the same technique used in the linked list implementation. Refer to lib/kernel/list.h for a detailed explanation.
이 체인 리스트는 동적 할당을 사용하지 않는다. 대신, 해시 테이블에 value로 들어갈 여지가 있는 page 구조체는 반드시 hash_elem을 멤버로 가져야만 한다. 모든 hash function은 struct hash_elem 위에서 동작한다. hash_entry 매크로는 hash_elem 구조체로부터 해당 elem을 갖고 있는 구조체(page!! hash table이 아님)로 전환한다.
hash_init()에서는 malloc()을 써놓고 동적할당을 받지 않는다고? 잘못 쓰여진 게 아니라, 아래 이미지를 보면 해시 테이블은 array와 linked list가 결합된 형태라는 것을 알 수 있다. 이때, array 형태인 bucket은 동적 할당으로 만들어주고, 그 bucket에 연결되는 hash_elem은 page 내에 들어있는 구조체 멤버이니 이는 해당 페이지를 생성할 때 만들어질 것이다. 따라서 이 연결 리스트에는 동적할당이 되지 않는다는 말임!

이제 SPT관련 주요 함수인 spt 초기화(init), spt 탐색(find), spt 삽입(insert)를 구현할 것이다. 그 전에, 이를 위한 보조 함수를 구현하자.
Helper Function 구현
unsigned page_hash() 추가
SPT에서 해시 값을 통해 value로 들어있는 페이지를 찾든 테이블에 삽입하든 기본적으로 hash 함수가 있어야 가상 주소를 hashed index로 변환할 수 있을 것이다. 이를 해주는 함수가 page_hash()이다. 해당 페이지 내 hash_elem을 받아와서 그 페이지의 가상 주소에 대해 hash_bytes() 함수를 통해 해시값을 반환한다. 실제로 해시값을 만드는 건 hash_bytes()이나 hash_elem으로부터 해당 페이지를 찾기 위해서 page_hash()를 감싸는 형식이다.
위의 주석에서도 나온 것처럼 hash_entry()는 해당 hash_elem이 들어있는 page의 주소를 반환한다. hash_entry()로부터 반환되는 것은 그 hash_elem을 멤버로 갖고 있는 페이지라는 것.
@/vm/vm.c
/* --- Project 3: VM --- */
unsigned page_hash (const struct hash_elem *p_, void *aux UNUSED) {
const struct page *p = hash_entry(p_, struct page, hash_elem); // 해당 페이지가 들어있는 해시 테이블 시작 주소를 가져온다. 우리는 hash_elem만 알고 있으니
return hash_bytes(&p->va, sizeof(p->va));
}
hash_entry() & hash_bytes()
hash_entry()
@/lib/kernel/hash.h
#define hash_entry(HASH_ELEM, STRUCT, MEMBER) \
((STRUCT *) ((uint8_t *) &(HASH_ELEM)->list_elem - offsetof (STRUCT, MEMBER.list_elem)))
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *) 0)->MEMBER)
hash_bytes()
Fowler-Noll-Vo 해시 함수를 이용해 buf_ 메모리 공간에 있는 정수를 size만큼 암호화시킨다. 이후 그 암호화된 해시값을 리턴한다.
/* Fowler-Noll-Vo hash constants, for 32-bit word sizes. */
#define FNV_64_PRIME 0x00000100000001B3UL
#define FNV_64_BASIS 0xcbf29ce484222325UL
uint64_t hash_bytes (const void *buf_, size_t size) {
/* Fowler-Noll-Vo 32-bit hash, for bytes. */
const unsigned char *buf = buf_;
uint64_t hash;
ASSERT (buf != NULL);
hash = FNV_64_BASIS;
while (size-- > 0)
hash = (hash * FNV_64_PRIME) ^ *buf++; // ^ : XOR(exclusive OR). 같으면 0, 다르면 1
return hash;
}
bool page_less() 추가
해시 테이블 내 두 페이지 요소에 대해 페이지의 주소값을 비교하는 함수 page_less()를 구현한다.
static unsigned less_func(const struct hash_elem *a, const struct hash_elem *b, void *aux) {
const struct page *p_a = hash_entry(a, struct page, hash_elem);
const struct page *p_b = hash_entry(b, struct page, hash_elem);
return p_a->va < p_b->va;
}
bool page_insert() 추가
해당 페이지에 들어있는 hash_elem 구조체를 인자로 받은 해시 테이블에 삽입하는 함수. 주어진 hash_insert()를 이용한다.
@/vm/vm.c
bool page_insert(struct hash *h, struct page *p) {
if(!hash_insert(h, &p->hash_elem))
return true;
else
return false;
}
bool page_delete() 추가
page_insert()와 동일한 구조.
@/vm/vm.c
/* --- Project 3: VM --- */
bool page_delete(struct hash *h, struct page *p) {
if(!hash_delete(h, &p->hash_elem)) {
return true;
}
else
return false;
}
보조 함수 구현이 끝났으니 주요 함수로 넘어간다.
주요 함수 구현
supplemental_page_table_init()
suppelement page table을 초기화하는 함수다. 각 페이지 테이블 별로 spt를 만들려면 먼저 초기화 작업을 해줘야 한다. spt 설계는 위에서 설명한 것처럼 다양한 방식으로 할 수 있는데, 우리는 해시 테이블을 쓰기로 했으니 해시 테이블로 구현한다.
void
supplemental_page_table_init (struct supplemental_page_table *spt UNUSED) {
/* --- Project 3: VM --- */
hash_init(&spt->spt_hash, page_hash, page_less, NULL);
}
여기서 hash_init()은 해시 테이블을 초기화하는 함수인데, 해시 함수 hash를 이용하여 해시 값을 계산하고 비교 함수 less를 이용해 해시 테이블 내 요소를 비교하는 테이블을 만든다.
hash_init()
bool hash_init (struct hash *h, hash_hash_func *hash, hash_less_func *less, void *aux)
{
h->elem_cnt = 0;
h->bucket_cnt = 4;
h->buckets = malloc (sizeof *h->buckets * h->bucket_cnt);
h->hash = hash;
h->less = less;
h->aux = aux;
if (h->buckets != NULL) {
hash_clear (h, NULL);
return true;
} else
return false;
}
spt init() 함수는 페이지 테이블이 처음 만들어질 때 함께 만들어져야 한다. 페이지 테이블은 언제 만들어질까? 처음에 process가 생성될 때 & fork로 만들어질 때 두 가지 경우에 해당한다. 따라서 initd()와 __do_fork()에서 초기화를 추가해준다. (이는 이미 적용되어 있음)
spt_find_page()
해시테이블에서 인자로 받은 va가 있는지를 찾는 함수. 인자로 받은 va(가상주소)가 속해 있는 페이지가 해시 테이블 spt에 있다면 이를 리턴한다.
/* Find VA from spt and return page. On error, return NULL. */
struct page *
spt_find_page (struct supplemental_page_table *spt UNUSED, void *va UNUSED) {
/* TODO: Fill this function. */
// struct page *page = (struct page *)malloc(sizeof(struct page));
// struct hash_elem *e;
/* 인자로 받은 spt 내에서 va를 키로 전달해서 이를 갖는 page를 리턴한다.)
hash_find(): hash_elem을 리턴해준다. 이로부터 우리는 해당 page를 찾을 수 있어.
해당 spt의 hash 테이블 구조체를 인자로 넣자. 해당 해시 테이블에서 찾아야 하니까.
근데 우리가 받은 건 va 뿐이다. 근데 hash_find()는 hash_elem을 인자로 받아야 하니
dummy page 하나를 만들고 그것의 가상주소를 va로 만들어. 그 다음 이 페이지의 hash_elem을 넣는다.
*/
struct page *page = (struct page *)malloc(sizeof(struct page));
struct hash_elem *e;
page->va = pg_round_down(va); //해당 va가 속해있는 페이지 시작 주소를 갖는 page를 만든다.
/* e와 같은 해시값을 갖는 page를 spt에서 찾은 다음 해당 hash_elem을 리턴 */
e = hash_find(&spt->spt_hash, &page->hash_elem);
free(page);
return e != NULL ? hash_entry(e, struct page, hash_elem): NULL;
}
spt_insert_page()
/* Insert PAGE into spt with validation. */
bool
spt_insert_page (struct supplemental_page_table *spt UNUSED,
struct page *page UNUSED) {
//int succ = false;
/* TODO: Fill this function. */
return page_insert(&spt->spt_hash, page);
}
일단은 여기까지가 과제에서 구현하라고 한 세 가지 함수.
3. Frame Management 관련 함수 구현
이외에도 추가로 구현해야 할 것들이 남아있다. Gitbook에 따르면, 모든 페이지는 메모리가 구성될 때 메모리에 대한 메타 데이터를 보유하고 있지 않다. 따라서 물리 메모리를 관리하기 위한 다른 방식이 필요하다고 한다. 바로, 물리 메모리 내 각 프레임 정보를 갖고 있는 frame table이다. 아래에서는 이를 구현하도록 한다.
frame table은 frame entry의 리스트로 구성된다. 현재 frame table 구조체에 대한 어떤 선언도 없으니, vm.c 위에 frame table 구조체를 리스트 형으로 선언해준다.
@/vm/vm.c
struct list frame_table;
이어서 frame table에 넣을 리스트 원소가 frame 구조체 내 멤버로 있어야 하니 frame 구조체를 수정해준다.
struct frame 구조체 수정
현재는 커널의 가상주소 kva와 frame과 연결된 가상 주소에 해당하는 페이지만 멤버로 있으며 해당 프레임을 리스트(frame table)에 연결하기 위한 구조체 멤버는 없는 상황이다. 프레임을 리스트에 연결하기 위해 list_elem 멤버를 추가해준다.
@/include/vm/vm.h
/* The representation of "frame" */
struct frame {
void *kva;
struct page *page;
struct list_elem frame_elem;
};이 frame 구조체는 프로세스의 커널 가상 주소에 위치해있다. frame->page는 해당 프레임과 연결된 가상 주소의 페이지를 뜻한다. (리마인드! 물리 메모리에서 우리가 말하는 페이지는 frame이라고 부르며 여기서 page라고 하면 무조건 가상 메모리에서의 페이지를 뜻한다!)
이제 frame 과 관련해 아래 세 가지 함수를 차례로 구현해본다.
vm_get_frame()
static struct frame *vm_get_frame (void);palloc()을 이용해 프레임을 할당받아온다. 만약 가용 가능한 페이지가 없다면 페이지를 스왑하고 이를 반환한다. 즉, 항상 유효한 물리 주소를 반환하는 함수이다. (공간이 없으면 이를 물리 메모리에서 디스크로 보내고 그 공간을 반환하니까) 즉, 유저 풀이 꽉 차있다면, 이 함수는 가용 가능한 메모리 공간을 얻기 위해 frame 공간을 디스크로 내린다.
프레임 테이블은 linked 리스트 형태로 구현한다. 여기서 프레임 테이블은 정확히 무엇인가? 사용 가능한 빈 프레임이 주루룩 연결되어 있는 연결리스트이다. 우리는 이 빈 프레임으로 구성된 프레임 테이블에서 특정 프레임을 찾아야 할 이유도 없으며, 그냥 이 비어있는 엔트리 중 하나를 가져다가 바로 가상 페이지와 연결해주고 싶을 뿐이다. 이렇게 하기에 가장 간단하면서도 목적에 맞는 자료구조가 바로 linked list이다. 빈 프레임을 프레임 테이블에서 바로 꺼내오는 알고리즘은 FIFO(First In, First Out)이다. 어차피 다 비어있는 애들이고 그 중 하나를 맨 앞에서 가져오면 되니까 시간복잡도는 O(1)이다.
/* palloc() and get frame. If there is no available page, evict the page
* and return it. This always return valid address. That is, if the user pool
* memory is full, this function evicts the frame to get the available memory
* space.*/
static struct frame *
vm_get_frame (void) {
struct frame *frame = (struct frame *)malloc(sizeof(struct frame));
/* TODO: Fill this function. */
ASSERT (frame != NULL);
ASSERT (frame->page == NULL);
frame->kva = palloc_get_page(PAL_USER); // user pool에서 커널 가상 주소 공간으로 1page 할당
if (frame->kva == NULL) { // 유저 풀 공간이 하나도 없다면
frame = vm_evict_frame(); // frame에서 공간 내리고 새로 할당받아온다.
frame->page = NULL;
return frame;
}
list_push_back(&frame_table, &frame->frame_elem);
frame->page = NULL;
return frame;
}
vm_evict_frame()
바로 위에서 구현하는 과정에서 vm_evict_frame()이 나왔다. 이 함수로 가보면 현재 구현이 덜 되어있는 상황이다. 이 함수는 page에 달려있는 frame 공간을 디스크로 내리는 swap out을 진행하는 함수이다. swap_out()은 매크로로 구현되어 있으니 이를 적용해주면 된다.
/* Evict one page and return the corresponding frame.
* Return NULL on error.*/
static struct frame *
vm_evict_frame (void) {
struct frame *victim UNUSED = vm_get_victim ();
/* TODO: swap out the victim and return the evicted frame. */
swap_out(victim->page);
return NULL;
}
비우고자 하는 해당 프레임을 victim이라 하고, 이 victim과 연결된 가상 페이지를 swap_out()에 인자로 넣어준다. 이때 swap_out()은 page_operations 구조체에 들어있는 멤버로 bool type이다. 즉, 실제 제거는 vm_get_victim()에서 진행하고 swap_out에서는 해당 프레임과 연결된 페이지 구조체 내에 있는 멤버 operations에 달린 swap_out을 건드린다.
@/include/vm/vm.h
#define swap_out(page) (page)->operations->swap_out (page)
struct page {
const struct page_operations *operations;
(...)
};
};
struct page_operations {
bool (*swap_in) (struct page *, void *);
bool (*swap_out) (struct page *);
void (*destroy) (struct page *);
enum vm_type type;
};
따라서 실제로 물리 frame에서 해당 정보를 지우는 건 vm_get_victim() 에서이다. 이 함수는 아직 덜 구현되어 있으니 마저 구현해보자.
vm_get_victim()
/* Get the struct frame, that will be evicted. */
static struct frame *
vm_get_victim (void) {
struct frame *victim = NULL;
/* TODO: The policy for eviction is up to you. */
struct thread *curr = thread_current();
struct list_elem *e, *start;
for (start = e; start != list_end(&frame_table); start = list_next(start)) {
victim = list_entry(start, struct frame, frame_elem);
if (pml4_is_accessed(curr->pml4, victim->page->va))
pml4_set_accessed(curr->pml4, victim->page->va, 0);
else
return victim;
}
for (start = list_begin(&frame_table); start != e; start = list_next(start)) {
victim = list_entry(start, struct frame, frame_elem);
if (pml4_is_accessed(curr->pml4, victim->page->va))
pml4_set_accessed(curr->pml4, victim->page->va, 0);
else
return victim;
}
return victim;
}for문을 돌면서 pml4에서 제거할 애를 찾는다. 이때 제거할 페이지를 찾는 알고리즘은 LRU 방식(linked list에서 가장 오래 전에 참조된 애를 제거) pml4_set_accessed()를 이용해 해당 프레임을 제거한다.
bool vm_claim_page (void *va);클레임은 물리 프레임을 페이지에 할당해주는 것을 의미한다. 처음에 위에서 구현했던 vm_get_frame() 함수를 호출해 frame을 받아온다. 이후, 인자로 받은 va를 이용해 supplemental page table에서 frame과 연결해주고자 하는 페이지를 찾는다.
/* Claim the page that allocate on VA. */
bool
vm_claim_page (void *va UNUSED) {
struct page *page = NULL;
/* TODO: Fill this function */
page = spt_find_page(&thread_current()->spt, va);
if (page == NULL)
return false;
return vm_do_claim_page (page);
}
bool vm_do_claim_page (struct page *page);
마지막..do_claim까지 구현하면 끝.
/* Claim the PAGE and set up the mmu. */
static bool
vm_do_claim_page (struct page *page) {
struct frame *frame = vm_get_frame ();
/* Set links */
frame->page = page;
page->frame = frame;
/* TODO: Insert page table entry to map page's VA to frame's PA. */
if(install_page(page->va, frame->kva, page->writable)) {
return swap_in(page, frame->kva);
}
return false;
}
'정글사관학교 개발일지 > 운영체제-PintOS' 카테고리의 다른 글
| PintOS Project 3 - Virtual Memory (3) Stack Growth (정글사관학교 80일차 TIL) (0) | 2022.01.21 |
|---|---|
| PintOS Project 3 - Virtual Memory (2) Anonymous Page (정글사관학교 79일차 TIL) (0) | 2022.01.20 |
| 운영체제 (5) 메모리 관리 - 3(정글사관학교 77일차 TIL) (0) | 2022.01.17 |
| 운영체제 (4) 메모리 관리 - 1, 2(정글사관학교 74일차 TIL) (2) | 2022.01.13 |
| 코딩을 잘한다는 것의 정의(정글사관학교 73일차 TIL - week 2 WIL) (0) | 2022.01.12 |