반응형
한동안 TIL 정리가 많이 밀렸다. 다시 정신차리고 가보자!!
메모리 관리 3
Multilevel Paging and Performance
- address space가 커지면 다단계 페이지 테이블이 필요하다. (why? 사용하지 않는 공간을 엔트리로 넣어야 하니 페이지 테이블이 커져서 비효율 증가)
- 이러면 페이지 테이블에 여러 번 접근해야 한다. ex) 4단계 페이지 테이블이면? 4번 접근해야 한다.
- 그런데도 다단계 페이지 테이블을 쓸 수 있는 이유는? TLB!
- ex) 메모리 접근 시간이 100ns, TLB 접근 시간이 20ns이고 TLB hit ratio = 98%라면?
- effective memory access time = 0.98 * 120(100*1 + 20*1) + 0.02 * 520(100*4 + 20*1) = 128ns
- 0.98* (20 + 100): TLB에 접근 1번 & TLB hit으로 해당 프레임 체크한 뒤 바로 물리 메모리에 접근 1번
- 0.02 * (20*1 + 100*4): TLB 접근 -> TLB miss로 메모리 접근 4번
- 하지만 결과적으로 페이지 테이블 하나(100ns)만 있을 때에 비해 28ns밖에 증가하지 않았음 & 메모리 공간 복잡도 효율성 엄청 증가했음!
- 따라서 TLB hit이 높다면 다단계 페이지 테이블 써도 괜찮다!
- effective memory access time = 0.98 * 120(100*1 + 20*1) + 0.02 * 520(100*4 + 20*1) = 128ns
- 이러면 페이지 테이블에 여러 번 접근해야 한다. ex) 4단계 페이지 테이블이면? 4번 접근해야 한다.
valid(v) / Invalid(i) bit in a page table
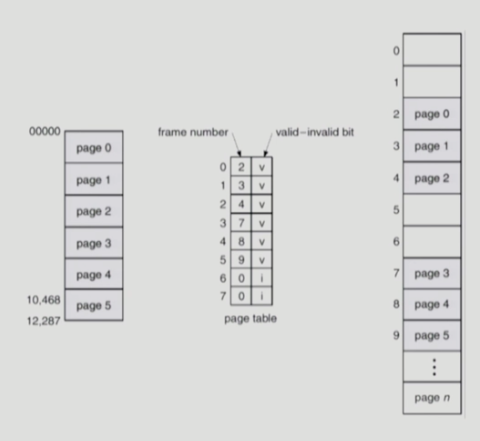
- 페이지 테이블에 frame number와 함께 저장되는 값: valid / invalid bit!
- 32비트 주소 체계를 쓰면 최대 1백만 개의 페이지 엔트리가 생긴다. (1 페이지 당 4KB / 가상 메모리 최대 용량: 4GB = 1M)
- 이때, 이 모든 페이지 중에는 중간에 사용하지 않는 주소 영역 역시 존재한다. 하지만 페이지 테이블 엔트리의 경우 사용하지 않는 메모리 영역에도 페이지 엔트리가 할당되어야 한다.(페이지는 할당되지 않았으나 테이블 엔트리에는 해당 페이지 번호가 달려있다는 말)
- why? 이는 페이지 테이블 자료 구조의 특성 때문이다! 현재 강의에서 페이지 테이블을 구현하는데 사용된 자료구조는 array. 즉, 연속적으로 엔트리가 나열된 구조이며 따라서 중간에 비어있더라도 해당 페이지 엔트리에 대한 번호는 array에 매겨질 수밖에 없다.
- 이렇게 하면 장점은 어떤 엔트리에 접근하든 O(1)의 시간복잡도를 가진다는 점 => 페이지 테이블 엔트리로부터 정확히 n번째 엔트리로 접근하기 위해서는 해당 값만큼 주소값을 더해주기만 하면 되니까! 일일이 위에서부터 하나씩 확인하면서 내려올 필요가 없다.
- 하지만 단점은 공간 복잡도가 O(n)이라는 것.
- 이러한 자료구조를 사용함으로 인해 페이지 테이블에는 해당 프레임 번호(물리 메모리 주소)외에도 이 페이지 테이블 엔트리가 유효한 (실제로 물리 메모리가 할당되어 있는)엔트리인지 체크하기 위해 v/i를 나타내는 비트(2가지 정보니까 1비트면 okay)를 사용!
- 만약 해당 엔트리가 valid라면 주소 변환 정보가 맞다는 뜻이니 해당 프레임으로 가면 valid한 정보가 들어있다는 의미가 된다!
Memory Protection
- 메모리 보호 측면에서 page table 각 엔트리마다 아래의 두 가지 비트를 설정해준다.
- 1. protection bit(2비트)
- 해당 페이지에 대한 접근 권한 정보를 뜻한다 (read/write/read-only)
- 페이지 중에는 코드 부분도 있고 데이터/스택 부분도 존재한다. 이 중 코드 부분은 접근 과정에서 내용이 바뀌면 안된다. 그러면 instruction이 달라지게 될테니 read-only로만 권한을 줘야 한다.
- 반면 데이터/스택은 접근 과정에서 페이지 내용이 달라질 수밖에 없으니 read/write 권한을 모두 줘야 한다.
- 2. valid-invalid bit(1비트)
- 위에서 설명했으니 패스
- invalid만 설명하면, 해당 주소에 연결된 물리 메모리(frame)에 유효한 내용이 없으니 접근을 불허한다.
- 이는 1) 프로세스가 그 주소 부분을 사용하지 않거나
- 2) 해당 페이지가 메모리에 올라와있지 않고 swap area(디스크)에 있거나를 뜻한다.
- 1. protection bit(2비트)
Shared Page
- shared code(re-entrant code)
- 동일한 프로그램이 여러 개 돌아간다고 할 때, 겹치는 코드가 있다면 이를 물리 메모리에 각각 올리는 게 아니라 한 놈만 올려서 이를 서로 다른 프로세스끼리 공유하도록 하는 방식을 뜻한다.
- 이는 두 가지 조건을 만족해야 함
- 1. read-only로만 페이지 접근 권한을 허용 => 프로세스 간에 하나의 code만 메모리에 올린다. (만약 수정해버리면 다른 프로세스가 해당 코드를 읽을 때 에러가 발생)
- 2. shared code는 모든 프로세스의 logical address space에서 동일한 위치에 있어야 한다.
- 프로세스가 만약 3개가 있다면, shared code에 있는 세 페이지가 동일한 physical address 뿐만 아니라 동일한 logical address 역시 가져야 한다!
- why? 동일한 physical addr을 갖는 것이야 공유해야 하니 당연한데 왜 동일한 logical일까?
- => 코드 컴파일 과정에서 보면 코드 안에 이미 논리 주소가 적혀있음. 즉, 코드를 어셈블리어로 바꾸는 과정에서 이미 코드와 어셈블리어 내 가상 주소가 1대1로 맵핑되어 있다는 뜻. 프로그램은 자기가 하나의 컴퓨터라고 인식하기 때문에 시스템 전체 단에서 서로 다른 프로세스 간에 가상 주소를 할당해주는 방식이 있지 않은 한 기본적으로 번역(컴파일)하면 그 안에 이미 가상 주소가 고정되어 있으니 같은 주소를 가질 수밖에 없다는 의미!
- 프로세스가 만약 3개가 있다면, shared code에 있는 세 페이지가 동일한 physical address 뿐만 아니라 동일한 logical address 역시 가져야 한다!
Segmentation
- 페이징이 동일한 크기 단위로 자르는 방식이었다면 세그멘테이션은 의미 단위로 분할하는 방법!
- logical address는 두 가지로 구성된다.
- segment-number
- offset
- segment table
- 각 테이블의 엔트리는 base와 bound(limit)을 갖는다.
- base: 세그먼트의 물리주소 시작점
- bound(limit): 세그먼트 길이(length)
- 각 테이블의 엔트리는 base와 bound(limit)을 갖는다.
- Segment-table base register(STBR)
- 물리 메모리에서의 segment table 위치
- Segment-table length register(STLR)
- 프로그램이 사용하는 segment 수
- 만약 s < STLR이면 세그먼트 수 s는 legal

- CPU가 논리주소를 주면 두 개로 분류
- 세그먼트 번호(s)
- 오프셋(d)
- 세그먼트 테이블 시작 위치는 레지스터가 갖고 있음!
- s만큼 떨어진 엔트리에 가면 해당 정보(base, limit)는 이 세그먼트가 물리 메모리 어떤 위치에 있는지를 갖고 있음.
- base: physical memory 0번지부터 base만큼 아래로 가면 해당 세그먼트 위치 나옴
- limit: 해당 세그먼트의 길이(페이지와 달리 세그먼트 길이는 세그먼트마다 다름!)
- s만큼 떨어진 엔트리에 가면 해당 정보(base, limit)는 이 세그먼트가 물리 메모리 어떤 위치에 있는지를 갖고 있음.
- 논리주소 세그먼트 번호 s와 레지스터 STLR 값을 비교 ⇒ s가 STLR보다 크면 trap! (addressing error)
- & 세그먼트 길이(limit)보다 offset(d)가 더 길지 않나 체크 ⇒ 더 길면 trap!
세그멘테이션이 페이징과 비슷한 면이 있지만 다른 측면 여러가지
- 오프셋 크기
- 페이지: 페이지 크기가 균일하기 떄문에 ⇒ offset 크기가 페이지 크기에 의해 알아서 결정
- 세그멘테이션: 32비트라 하면 offset에 해당하는 부분을 결정해줘야!
- 세그먼트 길이는 오프셋으로 표현할 수 있는 비트 수 이상은 안된다. ⇒ 세그먼트 길이를 제한하는 요소
- ex: segment 길이는 d의 최댓값 이상으로 커질 수 없다!
- 세그먼트 길이는 오프셋으로 표현할 수 있는 비트 수 이상은 안된다. ⇒ 세그먼트 길이를 제한하는 요소
- 물리 주소로 주소 변환 방법
- 페이징: 시작 주소(base)가 물리 프레임 번호! ⇒ 몇번 페이지 프레임으로 가면 되는지 결정
- 세그멘테이션: 정확한 바이트 단위 주소로 매겨줘야(세그먼트마다 크기가 다 다르니)
- hole 문제!
- 페이징:
- 세그멘테이션: 연속할당이다보니 크기가 균일하지 않아 중간중간에 hole이 발생(first-fit, best-fit 사용해줘야) ⇒ 외부 단편화 발생!
- but 장점? but 의미 단위로 작업하면
- 의미 단위로 권한을 부여하는 게 많기에!
- ex) 어떤 애는 read만 가능 / 어떤 애는 write만 가능 등등
⇒ 정리!
- 장점: 의미 단위로 작업하면 각각 의미 별로 권한을 부여해서 좋다는 장점 (공유, 보안 측면에서 페이징보다 효과적)
- 단점: segment 길이가 동일하지 않으므로 가변 분할 방식에서와 동일한 문제가 발생 (hole!)
Segmentation Architecture 특징
- Protection
- 각 세그먼트 별로 protection bit가 있다
- 각 entry:
- valid bit = 0 → illegal segment
- Read / Write / Execution 권한 갖는 bit
- Sharing
- shared segment
- same segment number
- **Segment는 의미 단위이기 때문에 공유와 보안에 있어 paging보다 훨씬 효과적!
- Allocation
- first fit / best fit
- 외부 단편화 발생
- ***segment 길이가 동일하지 않아 가변 분할 방식에서와 동일한 문제점 발생!
반응형