Ch.14 구조체(Struct)
배열에 여러 가지 정보를 매번 추가해야 한다고 생각해보자. 예컨대 도서 관리 프로그램을 만든다고 할때, i번째 책에 대한 정보를 저장한다. 책 이름, 저자, 출판사, 대출 횟수를 저장하려면 다음과 같은 i-1번째 순서에 다음과 같이 변수를 입력한다.
book_name[i-1], auth_name[i-1], publ_name[i-1], borrow[i-1]
근데 더 적을 것도 없이 객체 개념을 떠올려보면 구조체가 왜 필요한지 생각하게 되는데, 이제까지 배웠던 C의 자료구조인 배열은 하나의 배열에 동일한 형만 담을 수 있다. 예를 들어, int 형 배열이면 int 값만, char 형이면 char만. 그런데 하나의 자료형에 여러 자료형을 담을 수 있다면 어떨까? 예를 들어 char도 담고, int도 담고. 위의 예시처럼 책에 대한 정보를 저장한다고 하면 책 이름, 저자, 출판사는 문자열이 들어가겠지만 borrow에서 대출 횟수를 저장하려면 int형을 담아야 한다. 이는 기존의 배열 형태로는 할 수 없는 작업이다. 따라서 이를 해결하기 위한 새로운 자료형을 정의하는데, 이것이 구조체이다.
구조체는 배열과는 전혀 다른 방식으로 여러 데이터를 구조화하는데, 기존 자료형을 조합해 새로운 자료형을 정의할 수 있도록 허용하는 방식이다. 이때, 자료형을 새로 정의한다는 말을 잘 이해해야 하는데, 자료형을 정의하는 것을 구조체를 선언한다고 잘못 이해하는 경우가 발생하기 때문이다. "선언"한다는 것은 컴파일러에게 메모리 공간의 확보를 지시하는 것이다. 따라서 구조체를 선언하기 위해서는 구조체를 정의한 이후에야 가능한 일이다. 즉, 구조체의 정의와 구조체의 선언은 다르다. 구조체의 정의를 구조체라는 자료형을 선언한다고 하고, 구조체의 선언은 그냥 구조체의 선언이라고 하면 된다.(고 한다. 출처는 여기.)
위 링크에서 좀 더 살펴보면 구조체는 우리가 아는 객체 개념과 유사한 것을 알 수 있는데, 그 출생 배경이 다소 비슷하다. 구조체는 컴파일러가 제공하는 편리한 도구로, 프로그래머가 1) 현실 세계의 실제 대상을 흉내내는 자료형을 정의하여 2) 이 자료형을 가지고 변수를 선언하고, 3) (포인터 구조체라면 초기화한 후) 의미적으로 정돈된 형태로 사용할 수 있게 해준다. (어디서 많이 본 말이지 않나? 특히 1번은 객체를 쓰는 이유와 완전 유사한데?)
구조체 내부에 존재하는 원소는 원소라고 하지 않고 멤버라고 한다.
더 디테일한 내용도 많으나 다 정리하기엔 시간이 부족하니 일단 여기까지. 자세한 건 그때그때 필요할 때마다 정리할 예정.
Ch. 18 동적 메모리 할당
앞에서 배우기를, C에서는 항상 배열을 정할 때 그 크기가 컴파일을 하는 순간에 확정되어 있어야 한다. 즉, 컴파일러가 배열의 크기를 추측하는 게 아니라 명확하게 인지할 수 있도록 알려줘야 한다는 것. 하지만 현실의 문제를 배열로 만든다고 생각할 때, 배열의 크기가 상황에 따라 유동적으로 바뀔 수밖에 없다는 것이 문제이다. 이런 경우에는 배열을 줄이거나 늘릴 수 없으니 결국 충분히 크게 배열을 설정할 수밖에 없는데 이러면 메모리가 낭비된다. 그러니 그때그때 상황에 따라 배열의 수를 입력으로 받고 그 수만큼 배열의 크기를 지정하면 얼마나 좋을까?
이를 해결해주는 게 바로 동적 메모리 할당이라는 방법이다. 말 그대로 동적(=가변적으로)으로 메모리를 할당하는 것. 예시를 보자.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int SizeOfArray;
int *arr;
printf("만들고 싶은 배열의 원소 수: ");
scanf("%d", &SizeOfArray);
arr = (int *)malloc(sizeof(int) * SizeOfArray);
// int arr[SizeOfArray]와 동일한 작업을 한 크기의 배열 생성
free(arr);
return 0;
}
어라? 여기서 말록이 나온다고? 했는데 충격받았다. malloc이 memory allocation의 약자였다니...! 이 malloc이라는 건 함수의 이름이며 memory allocation의 약자이다. 이 함수는 <stdlib.h>에 정의되어 있기 때문에 #include <stdlib.h>를 추가해줘야 한다. (이름을 보니 대략 standard library인듯)
이 함수는 인자로 전달된 크기의 바이트 수(=SizeOfArray)만큼 메모리 공간을 만든다. 즉, 메모리 공간을 할당한다. 우리가 SizeOfArray인 int형 배열을 만들기 위해서는 당연히 (int의 크기) * (SizeOfArray) 가 될 것이다. 이때, int 타입의 크기를 정확하게 알기 위해서는 sizeof 키워드를 사용한다. sizeof는 이 타입(여기서는 int 형이니 4바이트)의 크기를 알려준다. 따라서 sizeof(int) * SizeOfArray를 malloc 함수에 인자로 전달해주면 된다. malloc 함수는 마치 사람이 엄청 많은 공원에서 원하는 크기의 돗자리를 깔아주고 사람들이 이리로 올 수 있도록 손을 흔들어주는 역할을 하는 것과 같다(고 책에 적혀있다.. 비유 무엇)
이 함수(malloc)는 자신이 할당한 메모리의 시작 주소를 리턴한다. 이때, 리턴형이 (void *) 형이므로 우리는 (int *) 형으로 형변환해서 arr에 넣어주면 된다. 결과적으로 arr은 int 형 배열의 시작 주소를 가리키는 int 형 포인터가 된다.
마지막에 free함수는 우리가 할당받은 메모리 영역을 다 쓰고 난 후에 다시 컴퓨터에게 돌려주는 역할을 한다. 이를 해제(free)한다고 하는데, 이 free를 제대로 하지 않으면 딱히 사용하지도 않는 메모리를 쓸데없이 자리만 차지하게 된다. 이 free를 제대로 하지 않아 발생하는 문제가 바로 메모리 누수(memory lear)이다. 이는 마치 공원에 돗자리를 깔아놓고서 그대로 집으로 돌아가는 것과 같다. 이 행위가 반복되면 어느새 공원에는 돗자리 천지가 되어 새로 깔 공간이 없게 될 것이다.
Heap: 메모리에서 malloc을 할당하는 공간
메모리에는 다양한 부분으로 이뤄져 있다. 스택, 데이터 영역, Read Only Data 부분은 malloc 함수가 건드릴 수 없다. 이 부분의 크기는 컴파일을 할 때 100% 딱 정해져 있어야 한다. 하지만 힙은 다른데, 메모리에서 힙 부분은 사용자가 자유롭게 할당하거나 해제할 수 있다. malloc 역시 이 힙을 사용한다. 따라서 위의 arr은 힙에 위치한다.
힙은 할당과 해제가 자유로운 만큼 제대로 사용해야 한다. 예컨대 힙에 할당하고 해제하지 않으면 공간이 낭비된다.
이제 동적 할당을 활용해 예제 코드를 짜보자.
/* 동적 할당의 활용 */
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int student; // 입력받고자 하는 학생 수
int i, input;
int *score; // 학생들의 수학점수 변수
int sum = 0; // 총점
printf("학생의 수는?: ");
scanf("%d", &student);
score = (int *)malloc(student * sizeof(int));
for (i = 0; i < student; i++) {
printf("학생%d의 점수: ", i);
scanf("%d", &input);
score[i] = input;
}
for (i=0; i < student; i++) {
sum += score[i];
}
printf("전체 학생 평균 점수: %d \n", sum / student);
free(score);
return 0;
}코드를 실행하면 학생 수 n과 학생 n명 각각에 대한 점수를 입력으로 받는다. 그러면 평균 점수를 출력한다.
2차원 배열의 동적 할당
이제 차원을 2차원으로 늘려서 배열을 동적으로 할당하는 방법에 대해 알아본다. 방법은 바로 포인터 배열을 이용하는 것(책에는 의외로 간단하다는데 무엇이 간단한 것인가..)
포인터 배열은 배열의 각 원소들이 모두 포인터인 배열이다. 따라서 각 원소들이 다른 일차원 배열을 가리킬 수 있다. 그러면 이 배열은 2차원 배열이 되는 것. 우리가 해야할 일은 먼저 포인터 배열을 동적으로 할당한 뒤에 다시 포인터 배열의 각 원소들이 가리키는 일차원 배열을 다시 동적으로 할당해주면 된다.
긴말 할 것 없이 코드를 보자.
/* 2차원 배열 동적 할당 */
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int i;
int x, y;
int **arr; // 우리가 만들려는 건 이차원 배열 -> arr[x][y] 이때 arr의 형은 int * => int 형을 가리키는 포인터 형
printf("arr[x][y]를 만들 것입니다. \n");
scanf("%d %d", &x, &y);
arr = (int **)malloc(sizeof(int *) * x);
// int* 형의 원소를 x개 가지는 1차원 배열 생성
for (i=0; i< x; i++) {
arr[i] = (int *)malloc(sizeof(int) * y); // for문 돌면서 각 배열 원소에 포인터 배정
}
printf("생성 완료! \n");
for (i=0; i<x; i++){
free(arr[i]); //해제
}
free(arr); //해제
return 0;
}이를 성공적으로 컴파일하면 아래와 같이 나온다.
arr[x][y] 를 만들 것입니다.
3
5
생성 완료!
이제 코드를 리뷰해보자.
int **arr;int array[3]이란 배열을 만들었다고 하면 array의 형은 무엇일까? int *이다. (배열에서 변수명은 배열의 주소값을 가리키는 포인터이기도 하니까). 그러면 int * arr[10];이라는 배열을 만들었다고 하면? arr의 형은 int **arr이다. 따라서 위에서 int **arr;을 선언한다.
arr = (int **)malloc(sizeof(int *) * x);그래서 arr은 포인터 사이즈에 해당하는 4바이트 크기의 방을 x 개만큼 힙에 동적으로 할당한다.

이때 arr 배열의 각 원소들은 int * 형이니 다른 int 배열을 가리키기를 갈망하고 있을 것이다. 그러니 아래 for 문에서 각 원소들에 다른 int 배열에 해당하는 메모리 공간을 짝지어준다.
for (i = 0; i < x; i++) {
arr[i] = (int *)malloc(sizeof(int) * y);
}

위 그림을 보면 각 원소들에 대해 메모리 공간을 할당하고 있다. arr[i]는 malloc이 정의한 또다른 공간을 가리킨다. 따라서 arr 하나의 원소가 크기가 y인 배열을 가리키고 있는데 arr 원소가 x개 이므로 전체적으로 보았을 때 총 x * y 배열을 가지는 셈이다. 이때 주의할 점은 arr[i]에 들어가는 건 malloc이 할당한 또다른 공간이 들어가는 게 아니라 4바이트 크기의 포인터이다. 이 포인터가 또다른 공간을 가리키는 것이지, 또다른 공간 자체가 arr[i]에 들어가는 건 아님.
때문에 이렇게 만들어진 배열은 정확히 말해 2차원 배열이라 말하기는 힘들다. 왜냐면 배열은 메모리에 연속적으로 있어야 하기 때문이다.

위 그림처럼 배열에서는 원소가 메모리 공간에 연속적으로 늘어서 있어야 한다. 하지만 위의 2차원 동적 할당 배열은 arr 원소가 가리키는 메모리 공간이 연달아 존재한다고 보장하지 않는다.
노드
대충 여기까지 정리하면 이제 연결 리스트 구현하고 RB트리로 넘어가도 될 것 같다...! 진짜..지긋지긋했다 C..
이제까지 여러 자료형을 배웠다. 변수를 무식하게 나열하는 것을 막기 위해 배열을 사용했고, 배열에 한계를 느껴서 구조체를 사용했다. 여기서 구조체 하나에 한 개 한 개를 다루는데 한계를 느끼고 구조체 배열을 이용했다. 결국 배열로 다시 돌아온 셈인데, 동적 할당을 해서 사용자가 원하는 크기의 입력을 다룰 수 있게 됐다고 해도 아직 많은 문제가 있다. 만약 사용자가 한 개의 입력을 더 받고 싶다고 해보자. 새롭게 동적할당을 하면 되지만 예를 들어 1000개의 데이터가 있는데 1개의 추가적인 데이터를 위해 1001개를 위한 공간을 새로 잡으면 너무 아깝다. 이를 해결하는 것이 바로 노드이다. 노드는 아래 그림과 같이 생겼다.

상당히 단순하게 생겼는데, 이를 C코드로 나타내면 다음과 같다.
struct Node {
int data; // 데이터
struct Node* next Node; // 다음 노드를 가리키는 부분
};
이 노드를 어떻게 사용할까? 아래 그림을 보자.

이를 말로 풀어보자. 첫 번째 노드가 다음 노드를 가리키면 다음 노드는 그 다음다음 노드를 가리키는 식으로 쭉 이어진다. 마지막 노드까지 이어지는데, 마지막 노드는 아무 것도 가리키지 않는다. 또한 각각의 노드는 데이터를 하나씩 가지고 있다. 다시 말해, 나중에 데이터를 한 개 더 추가하려고 하면 마지막 노드에 새 노드를 만들어서 이어주기만 하면 된다.
뿐만 아니다. 기존 배열에서는 거의 불가능했던 작업인 "배열 중간에 새 원소 집어넣기"가 가능해진다. 즉, 노드 사이에 새로운 노드를 끼워 넣을 수 있게 된다.

위 그림처럼 기존 연결을 끊어내고 그 사이에 새로운 노드를 연결해주면 된다. 이를 바탕으로 노드를 만들어보자.
가장 먼저 새로운 노드를 생성하는 CreateNode 함수부터 만든다. 이 함수는 노드를 생성하기만 한다. 노드를 생성하기 위해서는 데이터와 이 노드가 가리키는 다음 노드가 필요한데 이 함수는 단순히 첫 번째 노드를 만드는 역할을 한다고 하고 nextNode를 NULL로 줘보자.
/* 새 노드를 만드는 함수: 이 함수는 노드를 생성하기만 한다. */
struct Node* CreateNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->nextNode = NULL;
return newNode;
}
따라서 CreateNode 함수는 위와 같이 만들 수 있다. malloc을 통해 노드를 메모리에 할당하였고 이 할당된 노드는 newNode가 가리키게 된다. 이제 newNode->data에 data를 집어넣고 이 노드가 가리키는 다음 노드를 NULL로 주면 된다.
사실 이 함수는 노드를 생성하기만 할 뿐 노드를 어떻게 관계짓지는 못한다. 따라서 어떤 노드 뒤에 새로운 노드를 생성하는 함수를 만들어야 한다. 이 함수를 InsertNode 함수라고 하자. 어떠한 노드 뒤에 올지 '앞에 있는 노드'에 관한 정보와 '새로운 노드를 위한 데이터'가 필요하므로 struct Node *current, int data를 인자로 가져야 한다.
/* curren라는 노드 뒤에 노드를 새로 만들어 넣는 함수 */
struct Node* InsertNode(struct Node* current, int data){
/* current 노드가 가리키고 있던 다음 노드가 after이다. */
struct Node* after = current->nextNode; // nextNode는 node 구조체 안에 만들어진 다음 노드 가리키는 포인터 구조체. 그것이 after라는 Node라는 구조체 가리키는 포인터에 배정
/* 새로운 노드를 생성한다 */
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
/* 새 노드에 값을 넣는다 */
newNode->data = data;
newNode->nextNode = after; // after에는
/* current는 이제 newNode를 가리킨다. */
current->nextNode = newNode;
return newNode;
}이 함수에 대한 설명을 그림을 보면서 해보자.
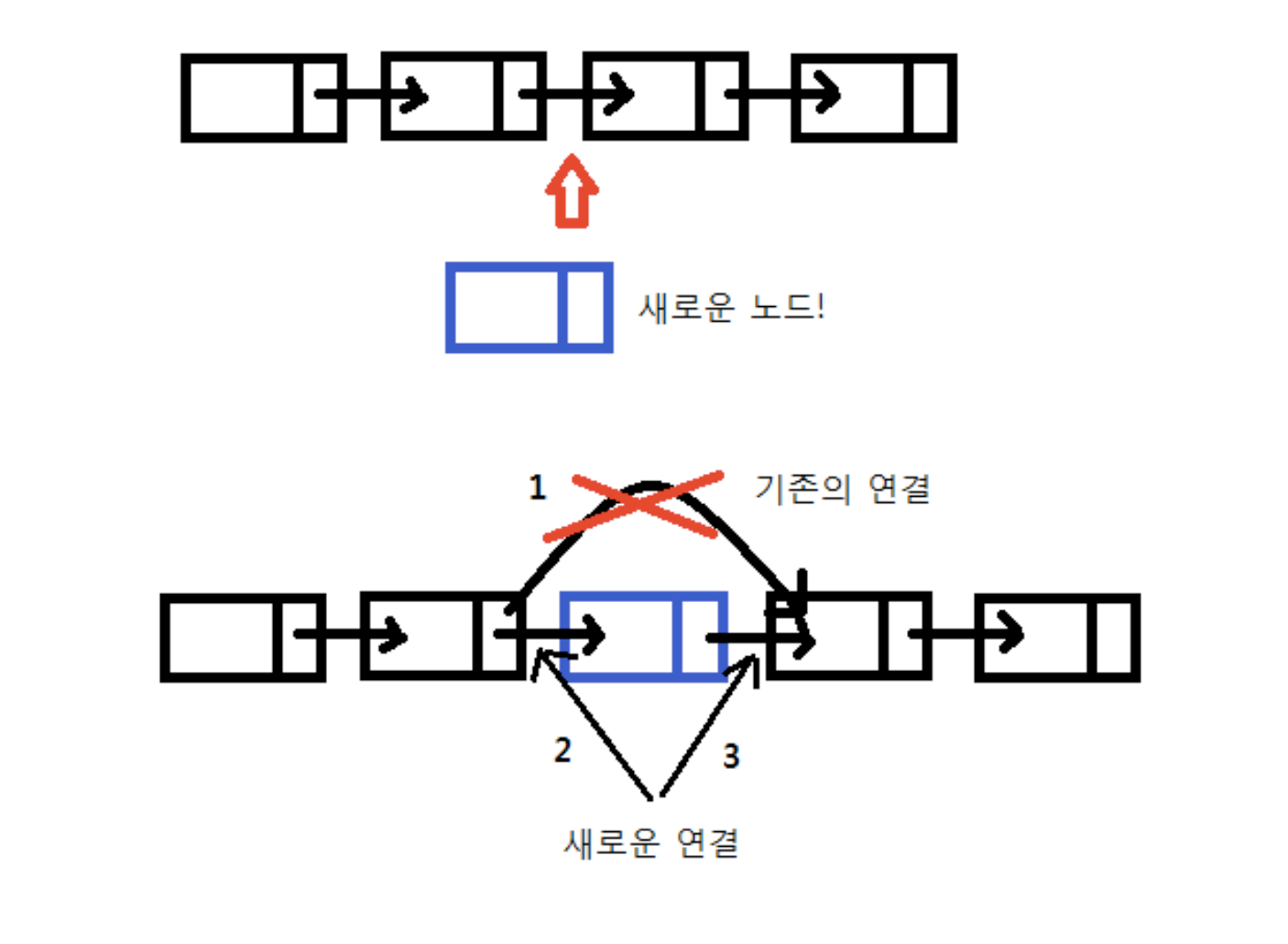
A. 새로운 노드를 생성한다.
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));위 문장을 통해 새로운 노드 newNode를 생성했다.
B. 새 노드에 값을 넣어준다.
newNode->data = data;
newNode->nextNode = after;이제 위 과정을 통해 newNode에 nextNode를 넣어주는 과정인데, 위 그림에서 3번에 해당한다.
C. current는 이제 newNode를 가리키게 된다.
current->nextNode = newNode;또한 newNode 앞(왼쪽)에 있던 노드의 nextNode가 바뀌었으므로(앞에 있던 노드는 이제 새로 들어온 newNode를 가리켜야 한다) 새롭게 수정하는 과정이 위 코드인데 이는 위 그림에서 1, 2번에 해당하는 과정이다.
그림에 나와있는 번호 순서를 다시 정리하면
3(새로운 노드를 먼저 오른쪽에 있는 nextNode에 연결)
-> 1, 2(왼쪽에 있던 current 노드의 nextNode가 newNode를 가리키도록 지시하면서(C) 1이 실행되고 곧이어 2번이 실행된다.)
이렇게 노드를 생성하는 함수를 만들었다면 노드를 파괴하는 역할을 가진 함수 역시 만들 줄 알아야 한다. 이를 위해서는 이 노드를 가리키고 있던 이전 노드가 필요하다. 그런데 이 노드를 가리키고 있던 노드를 찾기 위해서는 맨 처음부터 뒤져나가야 하는데(가리키는 방향을 거꾸로 알려주지 않으니) 맨 처음 노드를 헤드라고 하며 노드를 파괴하는 DestroyNode 함수는 헤드를 인자로 받는다. 파괴하려는 노드 역시 같이 인자로 받는다.
전체 코드를 쓰면 아래와 같다.
#include <stdio.h>
#include <stdlib.h>
struct Node* InsertNode(struct Node* current, int data);
void DestroyNode(struct Node* destroy);
struct Node* CreateNode(int data);
void PrintNodeFrom(struct Node* from);
struct Node {
int data; // 데이터
struct Node* nextNode; // 다음 노드를 가리키는 부분
};
int main() {
struct Node* Node1 = CreateNode(100); // 100이라는 데이터를 갖는 노드1을 생성
struct Node* Node2 = InsertNode(Node1, 200); // 노드1 뒤에 200이라는 데이터를 갖는 노드 2 삽입
struct Node* Node3 = InsertNode(Node2, 300); // 노드 2 뒤에 노드 3 삽입
// Node2 뒤에 Node 4 넣기
struct Node* Node4 = InsertNode(Node2, 400); //노드 2 뒤에 노드 4 삽입
PrintNodeFrom(Node1);
return 0;
}
void PrintNodeFrom(struct Node* from) {
// from이 NULL일 때까지, 즉 끝부분에 도달할 때까지 출력
while (from) {
printf("노드의 데이터: %d\n", from->data);
from = from->nextNode
}
}내일은 본격적으로 rb 트리를 구현하기 전에 거쳐야 할 연결 리스트와 스택을 구현해보기로. 이제 얼마 안 남았다...! 가자!
'정글사관학교 개발일지 > 자료구조&알고리즘' 카테고리의 다른 글
| 정글사관학교 41일차 TIL: 두 수의 덧셈(Leetcode #2: add-two-numbers) (0) | 2021.12.13 |
|---|---|
| 정글사관학교 35일차 TIL: 이진탐색트리 with 연결 리스트, make & Makefile (0) | 2021.12.07 |
| 정글사관학교 33일차 TIL: C언어 기초 - 포인터, 함수 (0) | 2021.12.04 |
| 정글사관학교 32일차 TIL: C언어 기초(문자 입력, 포인터) (0) | 2021.12.04 |
| 정글사관학교 31일차 TIL: 계단 오르기(#2579), 내리막길(#1520), C언어 기초 (0) | 2021.12.03 |