지난 포스팅에 이어서 진행.
정글사관학교 40일차 TIL: 동적 메모리 할당(malloc), 힙 단편화(fragmentation)
malloc: Dynamic memory allocation(동적 메모리 할당) Dynamic Memory Allocator 우리는 왜 동적 메모리 할당을 이용할까? C언어에서는 배열을 만들 때, 반드시 그 사이즈를 미리 선언해줘야 한다. 예컨대 2학년..
woonys.tistory.com
이번에는 가장 기본으로 구현하는 Implicit free list(묵시적 가용 리스트)부터 정리해본다. 번역한 단어가 영 입에 감기지 않아 여기서는 implicit이라고 부르겠다.
Implicit free list(묵시적 가용 리스트)
allocator는 블록 간 경계를 구분하고 할당된 블록과 가용 블록을 구분하는 데이터 구조를 필요로 한다. 이 정보를 블록 내에 저장한다. 힙 블록의 형태를 이미지로 살펴보자.
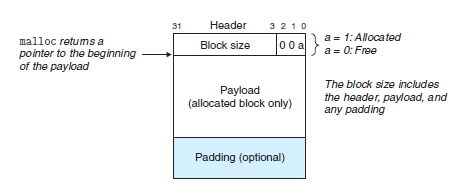
위 블록은 하나의 간단한 힙 블록을 이미지로 나타낸 것이다. 위에서부터 차례대로 header, payload, padding으로 구성된다.
- Header: 1 word(4바이트) 짜리 블록 한 칸에 헤더를 배정한다. 해더는 블록 크기(헤더 및 추가적인 패딩을 싹다 포함해)와 블록이 할당된 상태인지 가용 가능한 상태인지를 반환한다. 위 이미지의 헤더 부분에서 block size 옆에 "00a"라 적혀있는 부분을 보면 이곳이 블록의 할당/가용 상태를 표시하는 영역이다. allocator는 32비트 gcc 컴파일러에서 8 바이트 더블 워드 정렬을 기준으로 구현한다고 했다. 따라서 블록의 크기는 항상 8의 배수여야 하고, 그렇기 때문에 끝 세 자리가 항상 0이 된다. (8을 2진수로 바꾸면 1000(2)이니까 8의 배수면 무조건 끝 세자리가 0) a = 1이면 할당된 상태 / a = 0이면 가용 가능한 상태라고 표시한다.
- Payload: 우리가 담으려는 실제 데이터가 담기는 영역이다. 택배를 보낸다고 할 때 header나 뒤에 설명할 padding은 택배 박스, 주소가 적힌 종이, 뽁뽁이 등이라고 하면 payload는 박스 내에 담긴 실제 물건(=데이터)이다. 이곳에는 오직 할당된 블록만 배정된다. malloc에서 데이터를 요청하면 요 부분만 따라온다.
- Padding: 데이터를 payload에 담고 나면 남는 공간을 패딩으로 채우게 되는데 이때 패딩의 크기는 가변적이다. 패딩을 해야 하는 이유는 1) 외부 단편화를 막기 위해 2) 정렬 요건(alignment requirement)를 만족하기 위해서이다.
위 블록을 여러 개 쌓아 힙을 연속된 블록의 배열로 구성하면 아래와 같이 나타난다.

위 그림에서 블록 덩어리 앞쪽(header 위치)마다 8/0, 16/1, 32/0 등이 적혀있는 것을 볼 수 있다. a/b라고 할 때, a는 해당 블록의 크기(bytes), b는 할당(allocated, 1)/가용(freed, 0) 상태를 나타낸다. 진한 하늘색은 패딩을 나타낸다.
정리하면, 32비트 컴퓨터라고 하면 8의 배수로 블록 사이즈를 만든다. 따라서 29비트 크기의 블록에만 정보를 저장한다. 끝자리 3비트는 늘 000이다. 여기서 마지막 끝자리는 할당/가용 정보를 추가해 0/1로 표시한다.
이러한 구조를 Implicit list라고 한다. Implicit은 free인 블록이 헤더 내 필드에 묵시적으로(=implicit) 연결되어 있다는 말인데, 이는 할당한 블록과 가용한 블록이 모두 연결되어 있다는(앞뒤로 연결) 뜻이다.
할당한 블록의 배치(Placing allocated blocks)
응용 프로그램에서 k 바이트만큼 메모리 할당을 요청하면 allocator는 free list를 검색해 k 바이트 블록을 충분히 담을 수 있는 free 상태의 블록을 찾는다(=fit). 이 블록을 찾는 방법도 여러 가지인데, 여기서 3가지를 소개한다.
First fit
First fit은 free 리스트를 힙 영역의 가장 맨 처음 헤더에서부터 찾아서 가장 첫 번째로 fit이 맞는 블록을 선택한다. list의 끝쪽에 큰 free 블록을 유지할 수 있다는 장점이 있으나 앞쪽에서 검색했던 영역을 뒤에서 할당할 때도 매번 찾으니 효율이 좋지 않다.
Next fit
Next fit은 first fit과 시작은 동일하나 first fit은 매 서치마다 list의 처음부터 시작하는데 next fit은 이전에 서치했던 영역은 pass하고 그 다음부터 출발한다. first fit보다는 훨씬 빠르나 더 나쁜 memory utilization을 가진다.
Best fit
모든 free 블록을 조사해 가장 작은 애들 중에서 fit이 맞는 block을 선택한다. 더 나은 utilization을 가지나 훨씬 많이 서치해야 한다.
나중에 배울 segregated free list를 이용하면 가장 효율적으로 찾을 수 있다고 한다.
가용 블록의 분할(Splitting Free Blocks)
allocator가 fit이 맞는 블록을 찾으면 그 다음에 얼마나 많은 free 블록을 할당할 것인지 결정한다. 이 부분에서는 답수님 블로그에 좋은 이미지가 있어 가져왔다.

위 그림처럼 24바이트짜리 free 블록에 a라는 블록을 할당할 때는 아무 문제가 없다. 그런데 24바이트 free 블록 전체에 b를 배정하면 어떻게 될까? 2칸만 자리를 차지하고 나머지 4칸은 공간이 남는 내부 단편화가 발생한다. 기본적으로 free 블록은 하나의 블록으로 구성되어 있기 때문에, 두 칸만 자리하면 나머지는 그냥 비어있긴 하지만 다른 블록이 와서 자리를 차지할 수 없는 상태가 된다. 따라서 이를 분할(split)해주면 나중에 4칸 짜리 블록이 왔을 때 자리를 차지할 수 있으니 공간을 훨씬 효율적으로 쓸 수 있게 된다.
추가적인 힙 메모리 획득(Getting Additional Heap Memory)
만약 allocator가 요청된 블록에 맞는 공간을 못 찾으면 어떻게 할까? 기존의 free 블록을 조합해 더 큰 free 블록을 만들어야 한다. 그러기 위해서는 힙 영역 내에서 물리적으로 인접한 블록끼리 병합해주는 작업이 필요하다. 문제는 병합을 해서 나온 가장 큰 블록 사이즈보다도 할당 요청한 메모리 크기가 클 경우이다. 이때는 커널에 요청해서 추가로 힙 메모리를 만들어달라고 해야 하는데, 이 함수가 바로 sbrk 함수다.
위 작업을 통해 allocator는 추가 메모리를 하나의 큰 블록으로 전환한 다음에 그 free list에 블록을 삽입한다. 결과적으로 요청 블록에 새 블록을 놓는다.
Free 블록 합체(Coalescing Free Blocks)
allocated된 블록을 가용 상태로 바꾸면 서로 free된 블록과 인접한 곳에 다른 free block이 있을 수도 있다. 아까 위에서 본 것처럼, 이런 상황에서 하나의 큰 free 블록으로 있는 게 아니라 작게 분할된 여러 free 블록으로 있게 되면 단편화가 발생한다. 이 경우에는, 실제로 내/외부 단편화와 달리 블록이 들어갈 공간이 있고 그 공간이 인접하게 연결되어 있음에도 free 블록끼리 분할된 상태라 단편화 현상이 발생한다. 따라서 인접한 free block을 합체하는 작업을 해줘야 한다. 이를 Coalescing이라 한다. 아래 이미지에서 가운데 영역에 16/0, 16/0 두 개의 Free 블록이 쪼개져있는 것을 볼 수 있다. 이를 합체하면 그 아래 이미지처럼 32/0인 하나의 큰 블록이 형성된다.


경계 태그 합체 (Coalescing with boundary tags)
위에서 coalescing에 대해 설명했다. 그런데 대체 allocator는 어떻게 합체를 구현할까? free로 만들려고 하는 블록을 current block이라고 할 때, current block의 header는 그 다음 block의 헤더를 가리키고 있다. 그래서 그 블록이 free인지 아닌지를 체크하고 비었다면 현제 헤더 사이즈에다가 이 블록을 더해서 합친다.
그런데 다음 블록이 아니라 이전 블록을 병합하려면 어떻게 해야 할까? 힙을 처음부터 쫙 스캔해서 current block에 도달하게끔 해야 하나? 그런데 이 방법은 current block의 위치가 힙 내에서 뒤로 갈수록, 힙의 영역 크기가 커질수록 병합하는 시간이 비례해서 증가한다. 즉, 효율적이지 않다는 말이다.
따라서 이를 해결하기 위한 방법으로 경계 태그(boundary tag)를 도입한다. 쉽게 말하면 기존의 헤더와 동일한 형태(동일한 4바이트에 들어있는 값도 헤더와 동일)를 블록 끝에도 붙이는데, 이를 footer라고 한다.
사실 조금만 생각해보면 footer라는 놈은 메모리 입장에서는 비효율적인 애다. header랑 모양도, 내용도 똑같은데 굳이 하나 더 만들 이유가 무엇인가. 하지만 free 블록을 효율적으로 찾는 관점에서 보면 얘기가 달라진다. 최종적으로 만들어지는 블록의 모양새는 아래와 같아진다.

'정글사관학교 개발일지 > 메모리 할당' 카테고리의 다른 글
| 정글사관학교 44일차 TIL: Explicit malloc 정리 및 구현 review (0) | 2021.12.15 |
|---|---|
| 정글사관학교 43일차 TIL: Explicit malloc 구현 (0) | 2021.12.15 |
| 정글사관학교 40일차 TIL: 동적 메모리 할당(malloc), 힙 단편화(fragmentation) (2) | 2021.12.12 |
| 정글사관학교 39일차 TIL: 가상 메모리(Virtual Memory) / CSAPP 9장 정리 (2) | 2021.12.11 |